Vishakh Padmakumar@vishakh_pk·Quote tweet
Really excited to have this dataset released to the community! There's a gap in our understanding of how users interact with coding agents at scale. SWE-chat fills that need to help shape the next generation of human-centered evals and training objectives for coding agents! 🤖🚀
JO
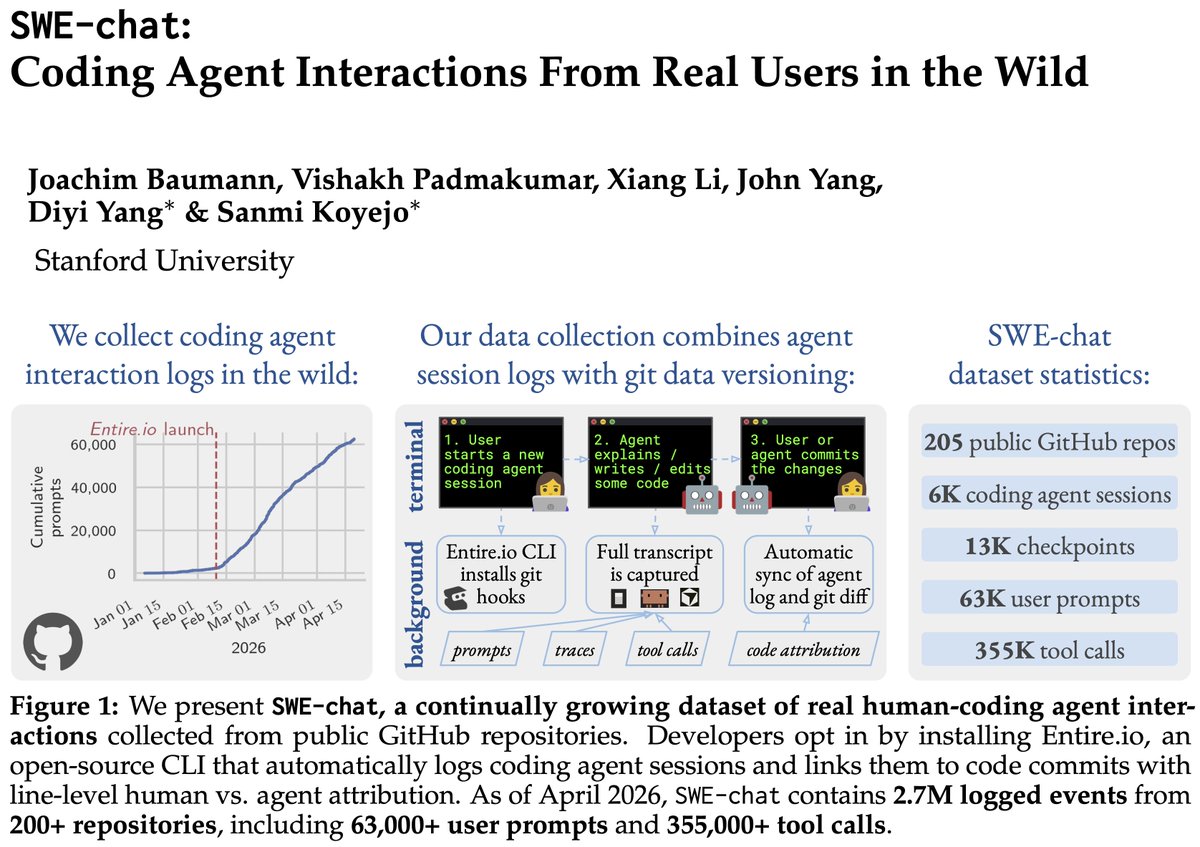
We present SWE-chat: the first large-scale dataset of coding agent interactions from real users in the wild. In 40% of real coding sessions, the agent writes ~all the code. Users push back 39% of the time – agents almost never stop to check. Data, paper, & findings in the 🧵👇