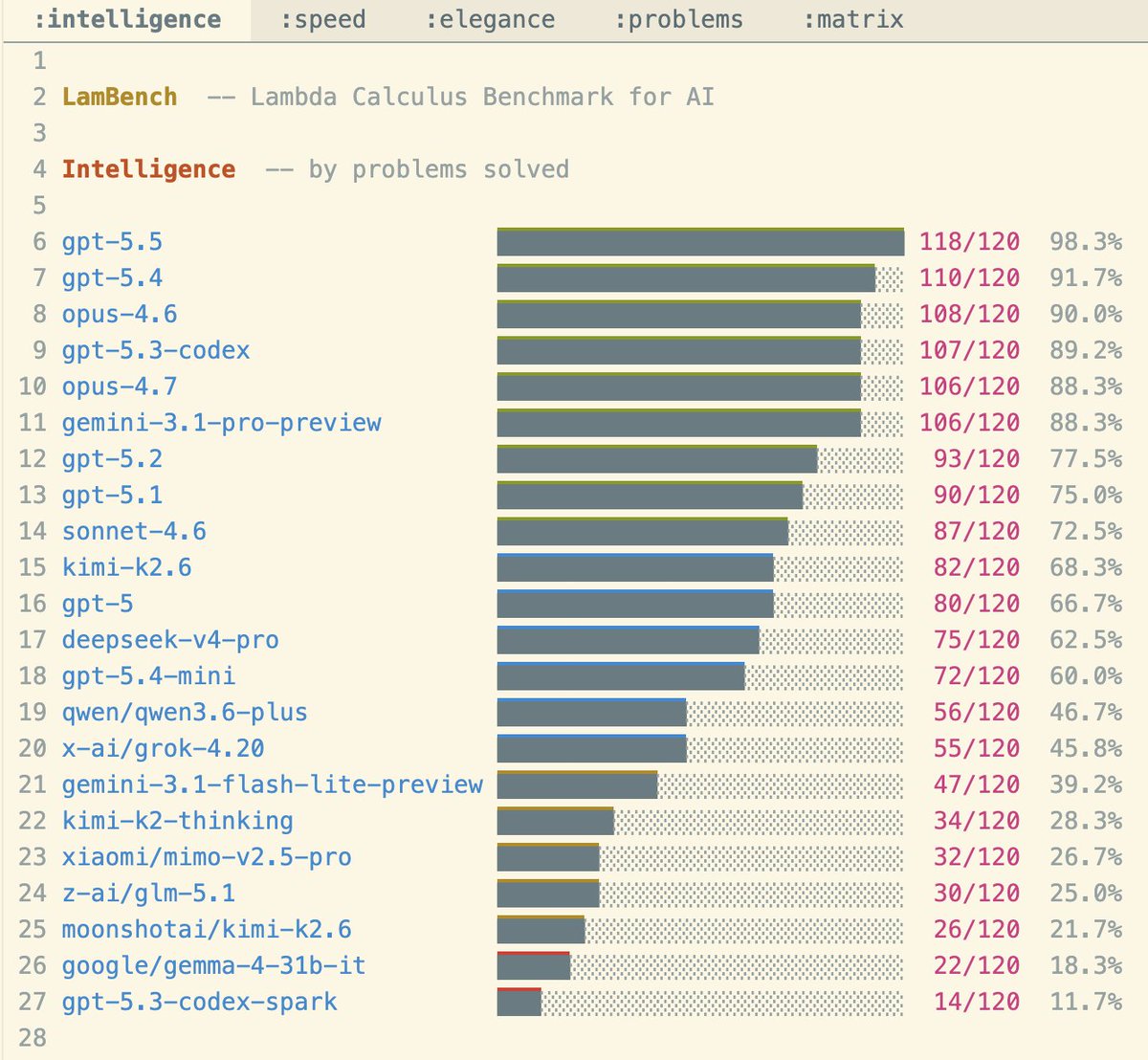
GPT 5.5 is much smarter than I thought Yesterday, I did one-shots, coding, benchmarks, and was disappointed. Today, I did it all again, except via the API, which is now available. Results changed completely: → one-shot prompts went from bad to very good → excellent coding outputs, on both pi and holefill → benchmarks jumped, and now GPT *dominates* I don't know what happened, I suppose there is something wrong with my Codex. In any case, truth is this model is very smart. It obliterated my benchmark, which is crazy because some of these problems were meant not to be solved. I'll need much harder tasks. I also fixed 2 bugs that affected some providers: → added a retry for lost connection → removed the timeout limit DeepSeek and Kimi wanted to spend more than 1 hour on my prompts, so I let them. Their results are much better now. Kimi K2.6 almost reaches Sonnet 4.6, although much slower. Also this shows my points from last post were wrong Again: this is a new vibe-coded bench, I'm focused on other things, so expect bugs and don't over-read this! GLM 5.1, Gemma, Grok are not updated yet.