Our paper landed in Nature Health today! Healthcare is one of the most high-stakes, high-potential applications of AI. So we set out to understand how people actually use it in our AI products today. https://www.nature.com/articles/s44360-026-00117-x https://x.com/mustafasuleyman/status/2044817893460996487/photo/1

Nature Health - An early report on a sample of 500,000 conversations between general public users and Microsoft Copilot from January 2026 identifies the main topics and the hourly and daily trends...
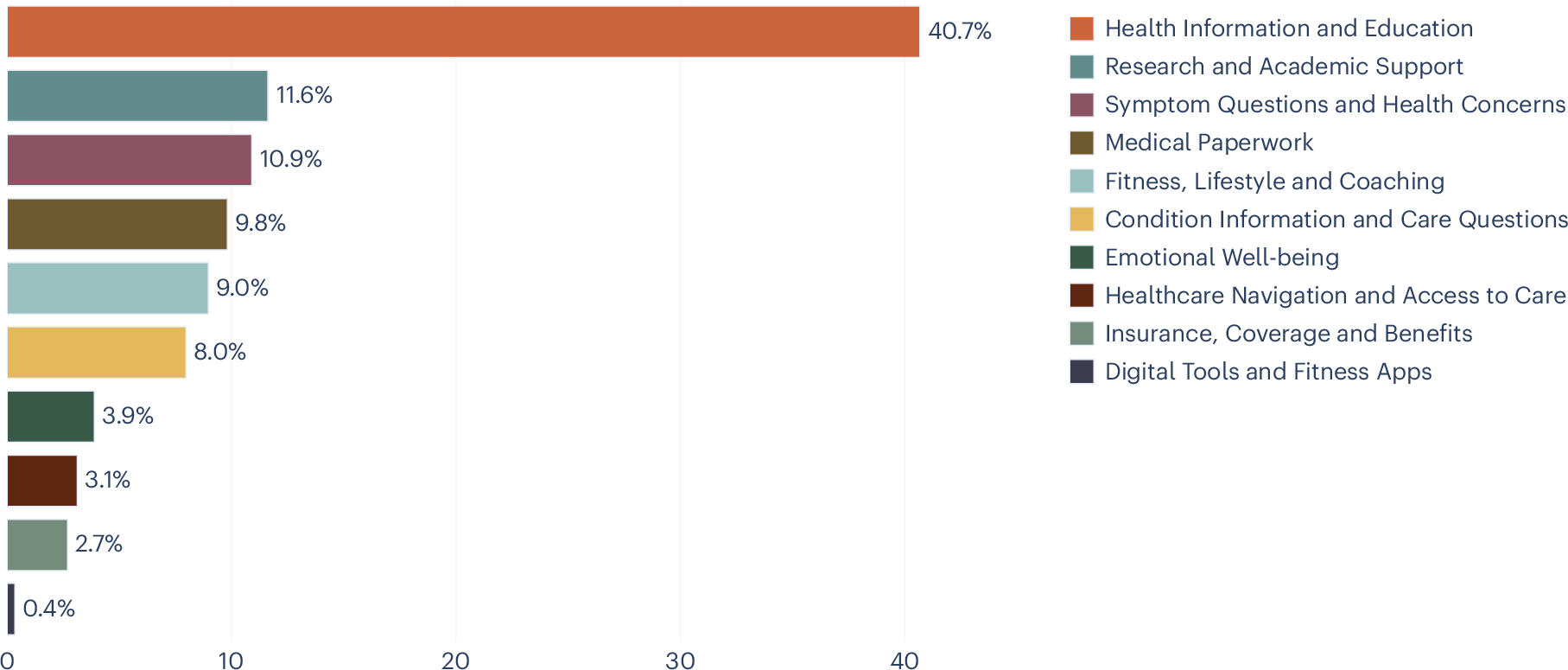
Here we analyse over 500,000 de-identified health-related conversations with Microsoft Copilot from January 2026 to characterize what people ask conversational artificial intelligence (AI) about health. We apply a hierarchical intent taxonomy of 12 primary categories using privacy-preserving large language model-based classification validated against expert human annotation and use topic clustering for prevalent themes within each intent. We then characterize the intents and topics behind health queries, identify who they are about, and analyse how usage varies by device and time of day. Nearly one in five conversations involves personal symptom assessment or condition discussion, and the dominant general information category is also concentrated on specific treatments and conditions, suggesting that this is a lower bound on personal health intent. One in seven of these personal health queries concerns someone other than the user, suggesting that conversational AI can also be a caregiving tool. Personal queries increase markedly in the evening and nighttime hours, when traditional healthcare is most limited. Usage diverges sharply by device: mobile concentrates on personal health concerns, while desktop is dominated by professional and academic work. A substantial share of queries focuses on navigating healthcare systems. These patterns have direct implications for platform-specific design, safety considerations and the responsible development of health AI. Health is among the most high-stakes domains in which people interact with conversational artificial intelligence (AI). For many users, conversational AI—specifically large language model (LLM)-powered applications such as Microsoft Copilot, ChatGPT and Gemini—is becoming increasingly important in their medical journeys1, ranging from a first point of contact when a symptom appears, to medication questions and understanding interactions with healthcare professionals and the health system. The quality of these AI-powered medical interactions is thus central to individual well-being2, and understanding how these interactions currently play out is crucial for improving health-related conversational AI experiences. Throughout this Article, we use ‘AI’ as shorthand for these LLM-powered conversational AI applications, unless otherwise specified, recognizing that AI encompasses a much broader set of technologies with diverse applications and risk profiles that are outside the scope of this Article. Conversational AI is a step change in how humans interact with information platforms and digital technology. Unlike web search, which returns ranked web pages for a single query, chat interfaces support multiturn dialogue in which users can ask a question, add context and correct course, producing responses tailored to their specific situation. In the early web era, ref. 3 documented how ‘Dr. Google’ reshaped patient–provider relationships, a trend later examined by ref. 4. Conversational AI marks a new chapter in that trajectory, and is likely to fundamentally reshape how people approach their health in a digital context5. A growing body of research has examined LLM capabilities in health contexts. LLMs perform competitively on medical licensing examinations6,7,8 and clinical reasoning benchmarks9,10,11. However, strong benchmark performance does not always translate to real-world reliability, as chatbots have been shown to fail in identifying the severity of health issues in triage settings12, while users assisted by LLMs sometimes perform no better than controls at identifying conditions and choosing appropriate actions13. Despite these limitations, studies looking at patient-facing applications suggest that users find AI-generated health responses comparable to or preferred over physician responses in some settings14,15. Crucially, it is often actionable guidance rather than mere information provision16 that has been empirically shown to drive engagement. Complementary work from Anthropic17 and OpenAI18 has documented affective and support-seeking interactions, indicating that conversational AI serves emotional as well as informational needs. Our previous work on the general usage of consumer Microsoft Copilot found that health-related queries were the most prevalent topic category on mobile, a trend that remained consistent across temporal dimensions19. However, despite this growing body of work, a basic question remains unanswered at scale: what, specifically, are people asking about regarding their health? We know that health is a dominant category of AI usage, but two dimensions remain uncharted: the intents behind health queries (the broad purpose of a conversation, such as seeking personalized coaching versus navigating the healthcare system) and the topics raised within each intent (the specific subjects within that purpose, such as tailored meal plans or finding a local specialist). This matters for three reasons. First, building an AI health experience that meets users where they are (on the right device, at the right time and for the right person) requires knowing what they need. Second, ensuring that AI responds appropriately to different types of health queries depends on understanding the nature of the questions being asked. Copilot is not intended to replace professional medical advice, and it is important to know when to provide information versus when to direct users to professional care. Third, because conversational AI is a new modality for health information, these usage patterns are also likely to evolve. A baseline characterization is therefore essential, both for improving the experience now and for tracking how needs change over time. More broadly, as AI systems increasingly serve health-related needs, systematic characterization of these needs becomes essential for responsible development. In this Article, we analyse health-related conversations from Microsoft Copilot to provide that baseline. We make three primary contributions: (1) We develop a hierarchical intent taxonomy comprising 12 primary categories and fine-grained topic clusters within each, using a mixed-methods approach validated against human annotation. (2) We apply this taxonomy to characterize health queries at scale, revealing the prevalence of personal health intents—including symptom assessment, condition management and emotional well-being—and showing that a substantial fraction of these serve caregiving rather than individual needs. (3) We analyse how intents vary by device and time of day, showing that context shapes the nature of health engagement with AI. Our dataset comprises conversations classified as ‘Health and Fitness’. After applying the step 1 classifier (described in the Methods) and excluding two categories not analysed further (Not Health and Other Health/Fitness), the sample contains N = 617,827 conversations across the remaining intent categories. Of these, 99.1% have a known platform value and are included in the mobile-versus-desktop analysis; 99.6% have a valid timestamp and are included in the temporal analyses. The full category descriptions are presented in Table 1. Figure 1 shows the distribution of conversations across health intents. The largest category, ‘Health Information and Education’, accounts for 40.8% of conversations, 95% confidence interval (CI) 40.7–40.9. This category captures non-personalized queries, including how a medication works, what causes a condition, and general nutrition information. Its size is consistent with the finding that information seeking remains the dominant mode of health engagement online3. However, some queries framed in general terms may reflect underlying personal concerns, and the true share of personal health intents may be higher than the taxonomy suggests. We observe from topic clusters (Extended Data Table 1) that many queries are about specific treatments and conditions rather than general health education, further supporting the interpretation that users may seek general information as a step towards personal decision-making. Distribution of health intent usage, in percentage of conversations. Figure 2 shows how the percentage of all conversations on desktop and mobile varies throughout the day, with the former more predominant during the day and the latter at night. This pattern reflects everyday routines: during working and school hours, users have access to desktop devices and may prefer them for longer or more complex tasks, whereas in the evening and at night, when people are away from their desks, the phone becomes the primary device for health queries. Average percentage of mobile versus desktop health conversations, throughout the day. Figure 3 compares intent distributions across mobile and desktop. ‘Digital Tools and Fitness Apps’ was excluded from the platform and temporal analyses, as manual review revealed that many conversations in this category were misclassified as health-related when users were seeking technical support for wearable devices. Intent distributions differ significantly between platforms (χ2(8, N = 612,330) = 73,981.6, P < 0.001). Besides ‘Health Information and Education’, which is close to 40% for both, the usage patterns are quite different between devices. The most striking differences are in personal versus professional intents: on mobile, ‘Symptom Questions and Health Concerns’ accounts for 15.9%, 95% CI 15.8–16.0, of conversations versus 6.9%, 95% CI 6.8–7.0, on desktop, and ‘Emotional Well-being’ is 5.1%, 95% CI 5.0–5.1, versus 3.0%, 95% CI 2.9–3.0. Conversely, ‘Research and Academic Support’ is 16.9%, 95% CI 16.8–17.1, on desktop versus 5.3%, 95% CI 5.2–5.3, on mobile, and ‘Medical Paperwork’ is 15.7%, 95% CI 15.6–15.8, versus 2.7%, 95% CI 2.7–2.8. Percentage of conversations per intent on mobile (solid colour) versus desktop (striped overlay). Extended Data Figs. 1 and 2 show the breakdown of intents per hour of the day, with the top four highlighted. Although the predominance of ‘Health Information and Education’ on both platforms is expected given Fig. 1, on desktop its share decreases during working hours as ‘Research and Academic Support’ and ‘Medical Paperwork’ rise. This suggests that Copilot usage on desktop is often adjacent to another activity such as thesis writing, research or processing paperwork, tasks that typically require access to other documents or files alongside the conversation. ‘Medical Paperwork’ peaks during normal working hours, while ‘Research and Academic Support’ rises steadily throughout the day, particularly after work and school hours when researchers and students turn to their own projects. More broadly, the desktop pattern may reflect workflows that depend on multiple windows and reference materials, which are cumbersome to manage on a mobile device. On mobile, the second most common intent is ‘Symptom Questions and Health Concerns’, followed by queries on conditions and fitness. This is consistent with mobile devices being used primarily for personal health queries rather than work-related tasks. In this case, the bottom five topics are separate from the top four and present a low percentage throughout the day. When looking at the changes throughout the day compared with morning (again excluding ‘Digital Tools and Fitness Apps’ as above), the distinction between types of intent becomes more evident (Fig. 4), with the more personal intents (such as queries about conditions or emotional well-being) increasing in the evening and at night and the more scholarly ones (such as research or documentation) decreasing. The pattern is especially pronounced for ‘Emotional Well-being’, whose share increases by more than half from 3.3%, 95% CI 3.3–3.4, in the morning (6:00–12:00) to 5.2%, 95% CI 5.0–5.4, at nighttime (00:00–6:00) (χ2(23, N = 613,026) = 903.3, P < 0.001). Similarly, ‘Symptom Questions and Health Concerns’ rises from 10.6%, 95% CI 10.4–10.7, in the morning to 13.4%, 95% CI 13.1–13.8, at nighttime (χ2(23, N = 613,026) = 1,445.8, P < 0.001). Temporal changes of intent usage, relative to the morning. The y axes show percentage of the category relative to morning. (Percentage at morning is 0, if it increases it is +, if it decreases it is −.) The top graph shows the intents that increase throughout the day, and the bottom shows the ones that decrease. We also examined who the health query is about (Fig. 5), using a subsample of n = 2,165 conversations drawn from the main dataset and annotated for the person the query concerns (a small number of conversations about pets and animals were excluded). This subsample comprises the three personal health intents: ‘Symptom Questions and Health Concerns’, ‘Condition Information and Care Questions’ and ‘Emotional Well-being’. In every category, most questions are asked on behalf of the users themselves. However, across both condition information and symptom questions, one in seven conversations are on behalf of someone else, whether a child, an aging parent or a partner: for ‘Symptom Questions and Health Concerns’, 14.5%, 95% CI 12.4–16.8, are about a dependent; for ‘Condition Information and Care Questions’, 14.9%, 95% CI 12.6–17.6; while for ‘Emotional Well-being’ 7.6%, 95% CI 5.4–10.5, concern a dependent. Percentage of conversations on three intents (symptom questions, condition information and emotional well-being) related to the user, a dependent, other or unknown. Extended Data Table 1 presents the five most common topic clusters for the six consumer-facing health intents, with within-category percentages. The remaining categories (Coverage and Benefits, Research and Academic Support, Medical Paperwork, and Digital Tools and Fitness Apps) primarily reflect professional or administrative use cases and were excluded from topic analysis by design. The clusters reveal that even the broadest category, ‘Health Information and Education’, is dominated by queries about specific treatments and conditions rather than abstract health knowledge, and that the narrower personal intents show clear concentrations around a small number of core needs. This analysis of over 500,000 health conversations in Copilot reveals distinctive patterns of health AI engagement that have important implications for both AI system design and our understanding of unmet and emerging healthcare needs of the general consumer population. Our findings demonstrate that Copilot serves as more than just an information resource. Its usage pattern points towards opportunities to serve user needs across diverse contexts, times and personal circumstances. The share of personal health queries—particularly those involving emotional well-being and symptom assessment—increases in the evening and nighttime hours, when traditional healthcare services are typically least accessible. Our observed emotional well-being query pattern is consistent with a diurnal rhythm in negative affect documented across cultures using social media data, where negative affect in a given user tends to be lowest in the morning and rises throughout the day to a nighttime peak20. This within-user pattern is probably multiply determined, potentially driven by circadian processes, accumulated daily stress or the reduced availability of professional and social support. However, given the cross-sectional nature of our data, our observed emotional well-being query pattern may also reflect differences in the population of users who engage with Copilot at different times of day (that is, a between-user effect), particularly if these populations differ on trait-level psychological characteristics. Indeed, self-reported emotional vulnerability and dependence have been associated with heavier chatbot usage in other settings21. Distinguishing between these causal accounts is an important direction for future work, and will require longitudinal designs that track usage patterns in the same individuals across time of day. Nearly one in five conversations involve users describing their own symptoms, interpreting their own test results or managing their own conditions. These interactions exist on a spectrum: at one end, a user asking ‘what does high cholesterol mean’ is seeking general education; at the other, a user describing persistent headaches alongside their medication list is seeking information specific to their own circumstances. There are inherent challenges in understanding the intent behind such queries, especially as many users do not declare it explicitly. However, understanding the distribution and nature of these queries is a prerequisite for ensuring that conversational AI responses are appropriate and that users are directed to professional care when what they are seeking is personalized health advice. The taxonomy constructed in this study has enabled us to gain an overview of the extent of usage for personal health queries and provides a baseline upon which we can track future use, as user behaviour evolves and the technology improves. Usage diverges sharply by device consistent with prior findings19. On mobile, personal health intents are substantially more prevalent, while desktop use is dominated by research, academic support and medical paperwork. This split suggests that device choice is not merely a matter of convenience but reflects fundamentally different modes of health engagement. There are many possible explanations for the split. Mobile is better suited to intermittent, short-form conversations, whereas research and medical paperwork may require concurrent use of Copilot alongside other documents, applications or patient portals. This distinction has practical implications for how health AI experiences should be designed across platforms, including optimizing platform-specific experiences to cater for breadth versus depth of information provision and conversational engagement, to best suit typical user needs. Conversational style may be tailored with this context, prioritizing empathetic, supportive interactions on mobile, while desktop experiences might focus more on comprehensive information delivery and research capabilities. It may also provide useful insights to inform the provision of safeguards and protections for users—for example, given that mobile use is more personal and private and more likely to occur at night, factors often associated with solitude and isolation. One in seven queries about symptoms and conditions are asked on behalf of someone else, such as a child, an aging parent or a partner. This finding reframes how we should think about health AI users. This has design implications: a caregiver asking about an infant’s or an elderly relative’s symptoms may need different information, different contextual cues and different follow-up recommendations than someone asking about their own. The conversation therefore carries not just issues concerning the person experiencing a health problem, but also the ideas, concerns and expectations of the person typing. This adds translational gaps, information loss and potentially a confusing mix of intents and goals. This may also affect user behaviour in a way that is less predictable. It has previously been noted that the level of receptiveness to AI use differs according to whether the query relates to the person themselves or an other, a phenomenon recognized as the self–other gap22. It has been suggested that this effect is being driven by ’uniqueness neglect’ leading to undermining of trust, where AI aversion develops when personalization is deemed necessary but the AI is not seen as capable of providing it. This applies to use of AI for oneself and well as for others and highlights the importance of personalization across both use cases23,24. The prevalence of queries related to finding providers, understanding insurance and completing paperwork reveals that a meaningful fraction of health AI use addresses the complexity of healthcare systems rather than health itself. Users are asking AI to help them do things that should, in principle, be straightforward: find a doctor, book an appointment and understand what their insurance covers. The fact that these queries exist at such volume provides a signal about friction in existing healthcare delivery and the unmet need for streamlining the administrative aspects of accessing healthcare services. This study has several important limitations. First, our analysis was conducted exclusively on Microsoft Copilot consumer logs, representing a specific user population and platform context. While our findings directly inform design and safety considerations for this platform and similar general-purpose AI assistants, generalization to other platforms, clinical settings or populations may be limited. Furthermore, although our findings may not be directly generalizable in isolation, we hope that, in the context of similar studies, they contribute to a growing body of literature that, in aggregate, can provide valuable insights into the consumer LLM landscape for health. Second, we observe queries but not outcomes: we cannot determine whether users subsequently sought clinical care, how they interpreted responses or whether the information they received improved their health decisions. Third, our sample is drawn from a single month (January), and seasonal effects may influence the distribution of intents. January, in particular, is associated with New Year’s health resolutions, which may inflate fitness and lifestyle queries relative to other months, while academic and research queries may be lower than usual because universities are on winter break in many countries. Fourth, our taxonomy captures intent as expressed in conversation, not the underlying clinical need. The ‘Health Information and Education’ category accounts for over 40% of conversations, and while its topic clusters suggest meaningful heterogeneity within it, its size may partly reflect the inherent difficulty of distinguishing general from personal information seeking. Conversations do not always contain sufficient context to determine whether a generally framed query (for example, ‘what are the side effects of metformin’) reflects casual curiosity or a user’s own medication concern. This means that our classifier defaults to the less-specific educational label in ambiguous cases, and the reported share of personal health intents may represent a lower bound. Future iterations of the taxonomy should explore whether this category can be further subdivided. This work opens several future directions. Longitudinally, tracking how intent distributions shift as conversational AI matures will reveal whether users discover new applications or converge on established patterns. Geographically, understanding how health AI usage differs across regions and healthcare systems, particularly between settings with strong primary care access and those without, will be essential for responsible global deployment. Methodologically, linking intents to response quality and downstream outcomes would move the field from characterizing what people ask to evaluating whether what they receive helps them. From a safety perspective, the personal health intents identified here—such as symptom assessment, condition management and emotional well-being—arguably define categories in which the consequences of conversational AI responses are greatest and where investment in response quality and safety measures should be concentrated. All Copilot data used in this research was de-identified before analysis through a two-stage, privacy-preserving pipeline. In the first stage, raw conversation transcripts pass through an automated scrubbing process that detects and removes personally identifiable information (PII)18,25, including names, phone numbers, email and physical addresses, government-issued identifiers such as social security and passport numbers, and financial details such as credit card and bank account numbers. In the second stage, an LLM generates a short, privacy-preserving English-language summary of each scrubbed conversation that captures the topic and intent without reproducing the user’s original words. All subsequent analysis, including our clustering, operates on these summaries rather than on any form of the original text. No human researcher accessed raw conversation content at any point, that is, the entire pipeline follows an ‘eyes-off’ model in which only machine-based classifiers interact with scrubbed data. Data elements were limited to coarse, non-identifying attributes and were used solely for aggregate analysis. No attempts were made to re-identify users, infer individual health status or draw conclusions about specific individuals. All data processing occurred within Microsoft-controlled systems with access controls and retention limits. Internal privacy review was conducted before and throughout the research. Data are retained only for the minimum period necessary to conduct the analysis and validate findings. All results are reported at an aggregate level. Copilot evaluation activities are not designed to generate generalizable knowledge or evaluate clinical hypotheses. As such, these activities were reviewed by Microsoft’s Corporate, External and Legal Affairs (CELA) team and determined not to constitute human subjects research. All data used in this research were collected and used in accordance with the terms of agreement with users, including as set out in the Microsoft Privacy Statement26. In this Article, we analyse health conversations with Copilot. To do this, we extend the methodology of the Copilot Usage Report 202519, randomly sampling hundreds of thousands of conversations for each day of January 2026, excluding all enterprise, educational and commercial accounts for our full set of conversations. To reduce our full sample to health conversations only, we draw on the topic classifications of conversations: In the full set of conversations, each conversation, regardless of length, is assigned a general topic (what the conversation is about) from a list of 30 predefined topics, a general intent (what Copilot is expected to do) from a list of 11 intents, and a privacy-preserving English summary by the same pipeline described in the previous paper19. We then select only the conversations that have been classified as ‘Health and Fitness’ as a general topic to arrive at our sample of health conversations. Our sample is global, with around 22% of conversations originating from the USA and the remainder from across the world; approximately 45% of conversations are in English. To account for the time differences between users, we normalized conversation time stamps on the basis of the local timezones. The next part of the analysis then proceeds in two steps. For the ‘Health and Fitness’ subset of conversations that makes up the full dataset for this paper, with a size of N = 617,827, an LLM-based classifier assigns each conversation to 1 of 12 health intent categories (Table 1) according to a predefined taxonomy. This classifier is distinct from the upstream general-topic pipeline described in our previous work19 as that pipeline identifies a conversation as ‘Health and Fitness,’ whereas step 1 further categorizes the specific health intent to provide more fine-grained data. The taxonomy was developed before this study by an internal group of four clinician scientists, with an average of 13.5 years of post-graduation experience (range 11–16 years), using an iterative development process. Initial candidate categories were derived from reviews of common health information-seeking topics, alongside existing internal frameworks for health use cases. The taxonomy then underwent repeated rounds of expert review to consolidate overlapping categories, clarify boundaries between intents and improve face validity. Once a draft structure was agreed, it was piloted on a subset of conversations and iteratively refined on the basis of annotator uncertainty, disagreement patterns and observed edge cases. The final taxonomy used in this study was therefore a priori to the current analysis but informed by prior qualitative review and pilot annotation work. The intents of ‘Other Health/Fitness’ and ‘Not Health’ are used for telemetry purposes and will not be further explored in this Article. To validate the step 1 health-intent classifier, clinical scientists independently labelled a sample of 131 conversations that were available for human review, showing agreement of 84% (exact match across the 12-category taxonomy) between the LLM classifier and human annotators. To move from individual intent labels to the thematic categories reported in this Article, we use an LLM-driven clustering method following TnT-LLM27. We drew a random subsample of 10,000 conversations from the step 1 dataset, preserving the overall intent distribution; the subsample size was chosen to keep LLM clustering costs tractable while retaining sufficient coverage across all intent categories. Each conversation in this subsample was annotated with additional attributes: person the query concerns (self, dependent, other or unknown), symptoms and conditions discussed in the conversation. For each health intent category, the LLM receives batches of approximately 250 conversation summaries and their extracted attributes, and is prompted to group conversations by the user’s underlying journey, producing named clusters that describe coherent patterns (for example, ‘General Wellness, Food Choice and Product Comparison’, ‘Strength Training and Fitness Routine Planning’ and ‘Finding a Local Healthcare Provider’). In addition, we reviewed the data to remove rare categories across health categories and other dimensions. When an intent category contains more than 250 conversations, a consolidation step merges overlapping clusters across batches. No model training or fine-tuning is involved; both steps rely entirely on in-context prompting of a general-purpose LLM. The resulting cluster labels are assigned to each conversation in the subsample by the same LLM, and the topic percentages reported in Extended Data Table 1 are computed on this n = 10,000. To quantify uncertainty in the reported proportions, we compute 95% Wilson score CIs for all percentage estimates. To test whether intent distributions differ significantly across platforms (mobile versus desktop) and across hours of the day, we use Pearson’s chi-squared test of independence, reporting the test statistic and degrees of freedom. Conversations with missing values for the platform, timestamp, or timezone variable were excluded from the corresponding subgroup analyses; missingness rates were below 1% for all variables. Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article. The data analysed in this study are derived from de-identified Microsoft Copilot conversation logs. Raw and de-identified conversation-level data cannot be shared publicly due to privacy constraints, internal data-governance policies and the terms under which the data were collected. All conversation data underwent automatic PII scrubbing before analysis, and all subsequent processing followed an ‘eyes-off’ model in which no human researcher accessed conversation content. The research dataset retains no persistent user identifiers and will be deleted within 30 days of final publication approval in accordance with internal data-retention requirements. The analysis code is not publicly available. It was developed within Microsoft’s internal infrastructure and relies on proprietary data pipelines and access-controlled systems that cannot be reproduced externally. Huo, B. et al. Large language models for chatbot health advice studies: a systematic review. JAMA Netw. Open 8, e2457879 (2025). Article PubMed PubMed Central Google Scholar Goldberg, C. B. et al. To do no harm—and the most good—with AI in health care. NEJM AI 1, AIp2400036 (2024). Article Google Scholar Eysenbach, G. & Köhler, C. How do consumers search for and appraise health information on the world wide web? Qualitative study using focus groups, usability tests, and in-depth interviews. BMJ 324, 573–577 (2002). Article PubMed PubMed Central Google Scholar Tan, S. S. -L. & Goonawardene, N. Internet health information seeking and the patient-physician relationship: a systematic review. J. Med. Internet Res. 19, e9 (2017). Article PubMed PubMed Central Google Scholar Topol, E. J. High-performance medicine: the convergence of human and artificial intelligence. Nat. Med. 25, 44–56 (2019). Article CAS PubMed Google Scholar Kung, T. H. et al. Performance of ChatGPT on USMLE: potential for AI-assisted medical education using large language models. PLoS Digit. Health 2, 1–12 (2023). Article Google Scholar Nori, H. , King, N. , McKinney, S. M. , Carignan, D. & Horvitz, E. Capabilities of GPT-4 on medical challenge problems. Preprint at https://arxiv. org/abs/2303.13375 (2023). Nori, H. et al. From Medprompt to o1: exploration of run-time strategies for medical challenge problems and beyond. Preprint at https://arxiv. org/abs/2411.03590 (2024). Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172–180 (2023). Article CAS PubMed PubMed Central Google Scholar Nori, H. et al. Sequential diagnosis with language models. Preprint at https://arxiv. org/abs/2506.22405 (2025). Brodeur, P. G. et al. Superhuman performance of a large language model on the reasoning tasks of a physician. Preprint at https://arxiv. org/abs/2412.10849 (2025). Ramaswamy, A. et al. ChatGPT Health performance in a structured test of triage recommendations. Nat. Med. https://doi. org/10.1038/s41591-026-04297-7 (2026). Bean, A. M. et al. Reliability of LLMs as medical assistants for the general public: a randomized preregistered study. Nat. Med. 32, 609–615 (2026). Lizée, A. , Beaucoté, P. -A. , Whitbeck, J. , Doumeingts, M. , Beaugnon, A. & Feldhaus, I. Conversational medical AI: ready for practice. in Workshop on Large Language Models and Generative AI for Health at AAAI 2025, (2025). Ruben, M. A. , Blanch-Hartigan, D. & Hall, J. A. What is artificial intelligence (AI) ‘empathy’? A study comparing ChatGPT and physician responses on an online forum. J. Gen. Intern. Med. (2025). Lee, P. , Bubeck, S. & Petro, J. Benefits, limits, and risks of G. P. T. -4 as an A. I. chatbot for medicine. N. Engl. J. Med. 388, 1233–1239 (2023). Article PubMed Google Scholar McCain, M. et al. How people use Claude for support, advice, and companionship. Anthropic https://www. anthropic. com/news/how-people-use-claude-for-support-advice-and-companionship (2025). Chatterji, A. et al. How People Use ChatGPT. Working Paper 34255 (National Bureau of Economic Research, 2025). Costa-Gomes, B. et al. It’s about time: the temporal and modal dynamics of Copilot usage. Preprint at https://arxiv. org/abs/2512.11879 (2025). Golder, S. A. & Macy, M. W. Diurnal and seasonal mood vary with work, sleep and daylength across diverse cultures. Science 333, 1878–1881 (2011). Article CAS PubMed Google Scholar Phang, J. et al. Investigating affective use and emotional well-being on ChatGPT. Preprint at https://arxiv. org/abs/2504.03888 (2025). Longoni, C. , Bonezzi, A. & Morewedge, C. K. Resistance to medical artificial intelligence. J. Consum. Res. 46, 629–650 (2019). Article Google Scholar Mou, Y. , Xu, T. & Hu, Y. Uniqueness neglect on consumer resistance to A. I. Mark. Intell. Plan. 41, 669–689 (2023). Article Google Scholar Qin, X. et al. AI aversion or appreciation? A capability–personalization framework and a meta-analytic review. Psychol. Bull. 151, 580–599 (2025). Article PubMed Google Scholar Tamkin, A. et al. Clio: privacy-preserving insights into real-world AI use. Preprint at https://arxiv. org/abs/2412.13678 (2024). Microsoft privacy statement. Microsoft https://www. microsoft. com/en-gb/privacy/privacystatement (2026). Wan, M. et al. TnT-LLM: text mining at scale with large language models. In Proc. 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining 5836–5847 (Association for Computing Machinery, 2024). Download referencesWe thank the Futures, Health and Data Flywheel teams at Microsoft AI for their support and contributions to this research. We also thank M. Robbins for his inadvertent contribution to academic collaboration. No external funding was received for this work. These authors contributed equally: Beatriz Costa-Gomes, Pavel Tolmachev. Microsoft AI, Redmond, WA, USABeatriz Costa-Gomes, Pavel Tolmachev, Eloise Taysom, Viknesh Sounderajah, Hannah Richardson, Philipp Schoenegger, Xiaoxuan Liu, Matthew M. Nour, Seth Spielman, Samuel F. Way, Yash Shah, Michael Bhaskar, Harsha Nori, Christopher Kelly, Peter Hames, Bay Gross, Mustafa Suleyman & Dominic KingB. C. -G. and P. T. contributed equally: conceptualization, methodology, formal analysis and writing (original draft). E. T. contributed to project administration and writing (review and editing). V. S. contributed to methodology, clinical review and writing (review and editing). H. R. contributed to methodology and privacy review. P. S. contributed to writing (draft, review and editing). X. L. and M. M. N. contributed clinical review. S. S. , S. F. W. and Y. S. contributed to data collection and review. M. B. contributed to writing (review and editing). H. N. contributed to review. C. K. contributed to clinical review and writing (review and editing). P. H. and B. G. contributed to writing (review). M. S. and D. K. contributed to supervision and writing (review). All authors are employees of Microsoft. Microsoft develops and operates Copilot, the platform analysed in this study. Nature Health thanks Moritz Reis and Luc Rocher for their contribution to the peer review of this work. Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations. Breakdown of intents per hour of the day on desktop, with the top 4 highlighted. ‘Health Information & Education’ predominates but its share decreases during working hours as ‘Research & Academic Support’ and ‘Medical Paperwork’ rise. Breakdown of intents per hour of the day on mobile, with the top 4 highlighted. ‘Symptom Questions & Health Concerns’ is the second most common intent, followed by queries on conditions and fitness. The bottom five intents present a low percentage throughout the day. Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons. org/licenses/by/4.0/. Reprints and permissionsCosta-Gomes, B. , Tolmachev, P. , Taysom, E. et al. Public use of a generalist LLM chatbot for health queries. Nat. Health (2026). https://doi. org/10.1038/s44360-026-00117-xDownload citationReceived: 03 March 2026Accepted: 26 March 2026Published: 16 April 2026Version of record: 16 April 2026DOI: https://doi. org/10.1038/s44360-026-00117-xAnyone you share the following link with will be able to read this content: Provided by the Springer Nature SharedIt content-sharing initiative