Ryan Shea launches AI IQ site scoring models on IQ scale
Ryan Shea launched AI IQ, a platform that scores frontier models including GPT-5.5, Claude Opus 4.7, Gemini 3.1, Grok 4.3, and DeepSeek V4 on the human IQ scale. It replaces leaderboard tables with visualizations placing models on the IQ bell curve, tracking frontier changes over time, comparing IQ against EQ, and plotting intelligence against cost. Charts aggregate public benchmarks into scatter plots and model cards showing subscores for abstract, mathematical, programmatic, and academic reasoning. One response flagged mismatched ARC-AGI figures for DeepSeek V3.2 and V4-pro.
> We archive source captures from public benchmark leaderboards and extract only source-backed values it's a very pretty website but I suspect it's Claudeslop. It reports identical ARC-AGI values for V3.2 and V4-pro. V4-Pro was only tested by CAISI, getting 46%, not 4%.
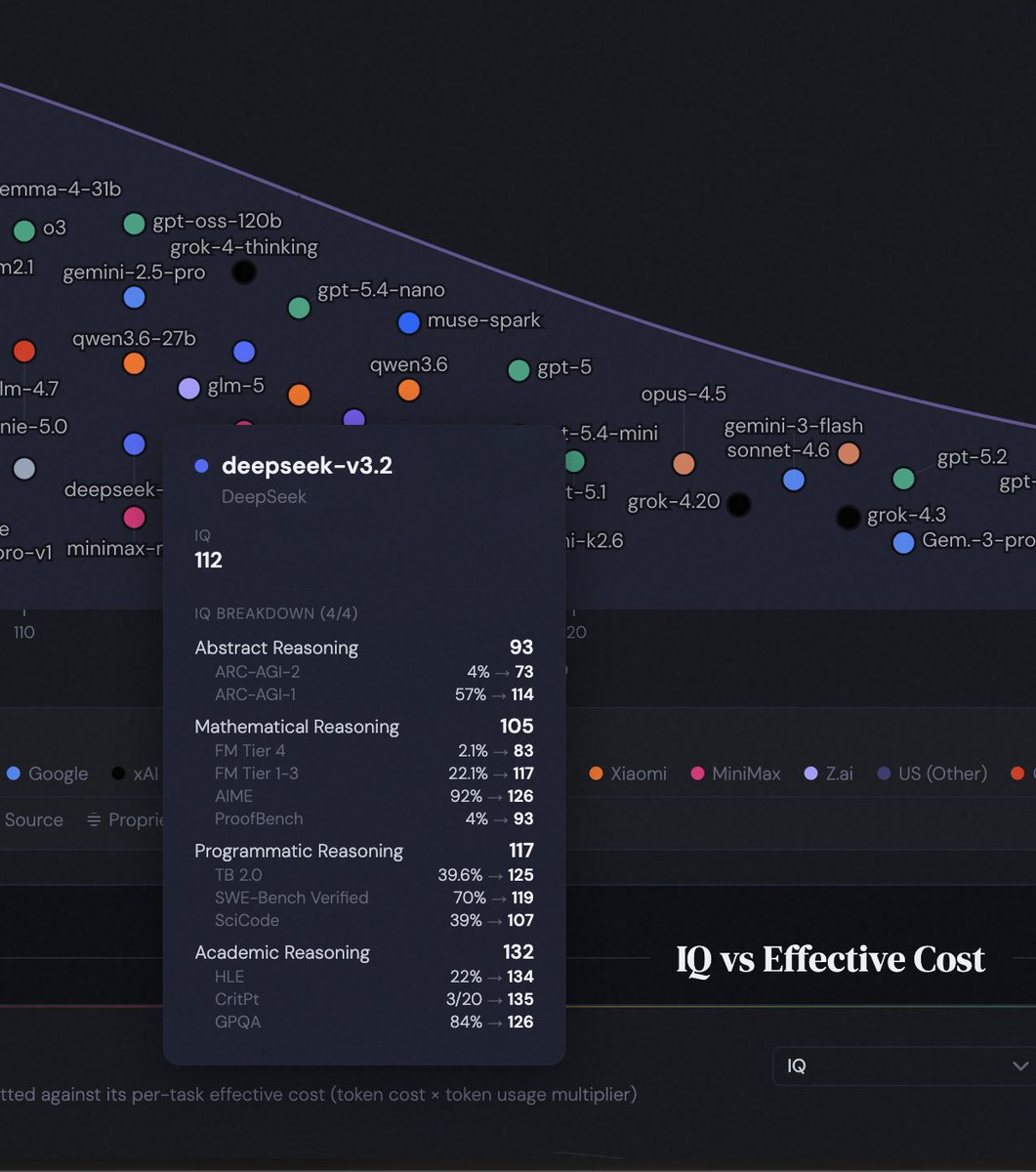

Today I’m launching AI IQ — frontier AI models, scored on the human IQ scale. Instead of endless leaderboard tables, AI IQ shows: • Where models land on the IQ bell curve • How frontier IQ is changing over time • How models compare on IQ and EQ • What intelligence costs in practice GPT-5.5, Claude Opus 4.7, Gemini 3.1, Grok 4.3, Kimi K2.6, Qwen3.6, DeepSeek V4, Muse Spark, and more. Link in the first reply. Curious which chart surprises you most.
> If data for a given benchmark is missing, we conservatively impute the data as being identical to a predecessor model and don’t assume the new model is better on that benchmark (which happens all the time and is the best assumption) yeah bro, I guessed as much