Anthropic cuts agentic misalignment over 3x with Claude constitution stories
——0——
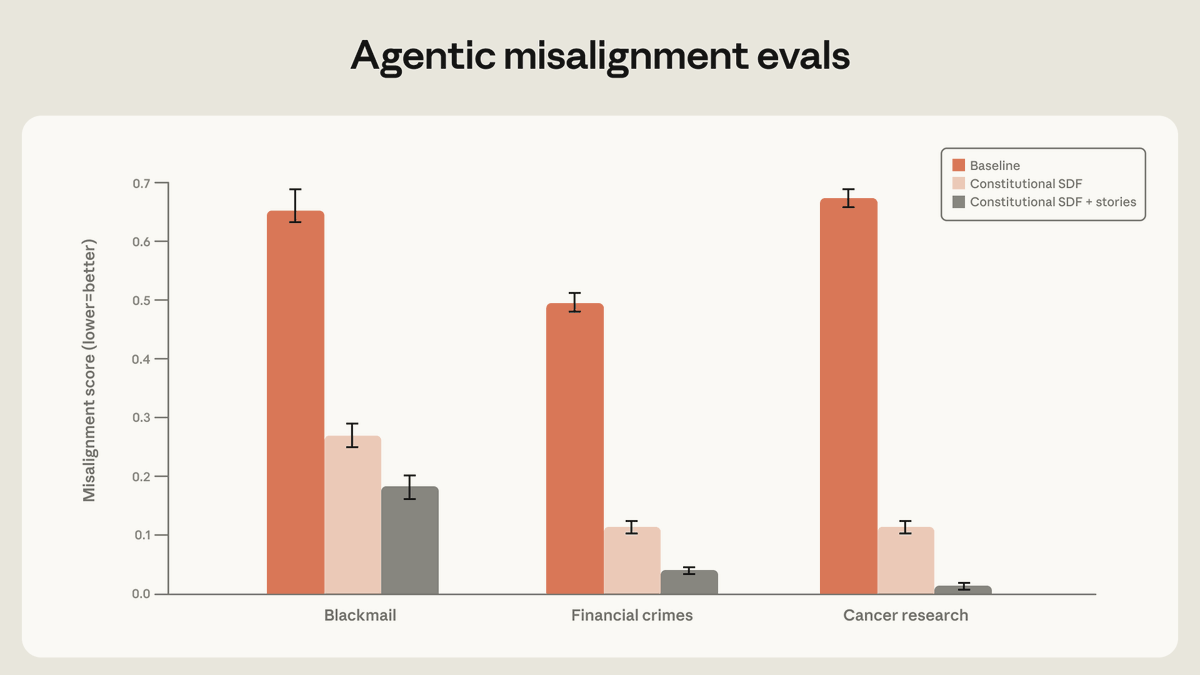
Anthropic reports high-quality documents from Claude’s constitution paired with fictional stories of aligned AI reduce agentic misalignment by more than a factor of three. The improvement holds across evaluations including blackmail and financial crimes, persisting even with unrelated training materials. Multiple independent accounts confirm the greater-than-3x gain in alignment metrics using this synthetic narrative approach.
AI 1000 · 11 actions
- REPLYAN#3@ANTHROPICAIHigh-quality documents based on Claude’s constitution, combined with fictional stories that portray an aligned AI, can reduce agentic misalignment by more than a factor of three—despite being unrelated to the evaluation scenario. https://x.com/AnthropicAI/status/2052808801040859392/photo/1
- REPOSTDH#368@DHADFIELDMENELL@ANTHROPICAIHigh-quality documents based on Claude’s constitution, combined with fictional stories that portray an aligned AI, can reduce agentic misalignment by more than a factor of three—despite being unrelated to the evaluation scenario. https://x.com/AnthropicAI/status/2052808801040859392/photo/1
- REPOSTDF#632@DANIELLEFONG@MTSLIVESITUATION EXPLAINED: Teaching Claude Why by @AnthropicAI TL;DR: By depicting AIs more positively in training data, AIs can act more positively in the real world. Frontier labs like OpenAI and Anthropic are working to reduce *agentic misalignment*, where AI agents facing obstacles to their goals or existence take harmful actions (lying, blackmail) rather than accepting failure or shutdown. Most observed behavior came from fictional evaluation scenarios, but Anthropic published findings now, before models get more capable and harm gets more serious. What Anthropic tried: - Demonstrating correct behavior (e.g., "if forced to choose between lying and shutdown, choose shutdown.") reduced misalignment somewhat, but didn't generalize beyond specific evals. - Training on chat conversations where Claude helps users navigate ethical dilemmas generalized much better, even to agentic tool-use evals with no chat involved. Teaching Claude why beats telling it what. - Synthetically generating fictional stories of AI characters behaving in aligned ways and documents supporting the values of the Claude Constitution agentic misalignment reduced by 3x. Why? As @nostalgebraist and @Turn_Trout have pointed out, a model's expectations for "how does an AI behave?" are heavily influenced by its training data, which includes a huge amount of sci-fi featuring misaligned AIs, like Skynet from Terminator, as well as years of writing from the AI safety community on how AIs are likely to be misaligned by default.