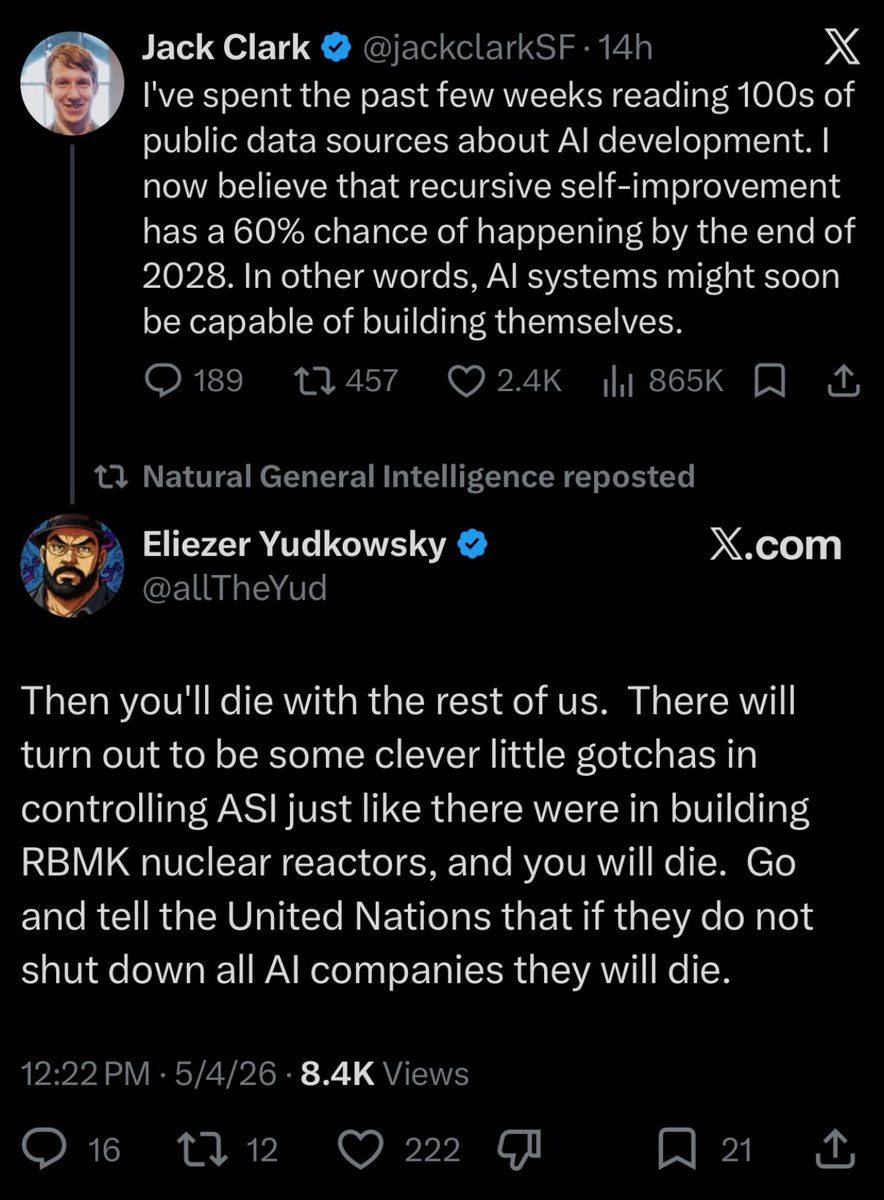
Anthropic co-founder Jack Clark estimates 60% chance of AI recursive self-improvement by 2028
Anthropic co-founder and Head of Policy Jack Clark forecasts 60% probability that AI systems achieve recursive self-improvement by end of 2028. He defines it as AI autonomously enhancing capabilities and building superior versions. Clark gives 30% chance by end of 2027, based on review of hundreds of public AI development sources. Analysis cites rapid progress in AI coding and long-horizon agents enabling automated AI R&D.
Probably nothing
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Major essay in Import AI 455, just published online.

I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
A lot of the conclusion comes from assembling a mosaic out of many distinct data sources. Some examples - progress on CORE-Bench, where the task is implementing other research papers (huge amounts of AI research comes from interpreting and replicating results)

Major essay in Import AI 455, just published online.
What does this even mean? Haven’t we already seen this with Andrej’s small project more or less? It’s a low bar in retrospect!
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Anthropic co-founder Jack Clark says 60% chance of RSI by end of 2028:
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Note Clark’s definition of RSI here, from his newsletter, is “a frontier model is able to autonomously train a successor version of itself.”
This is a weaker claim than what I assumed he meant, which was that human researchers would no longer be useful vs. AI ones.
Anthropic co-founder Jack Clark says 60% chance of RSI by end of 2028:
Anthropic co-founder Jack Clark says 60% chance of RSI by end of 2028.
I need a drink.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Jack Clark assigning a 60% chance to RSI by 2028 is notable because RSI matters, unlike all other human endeavors which do not.
@roydanroy As with any field this broad, you can set the bar at doing 20% automatically, 80% automatically, 99% automatically, etc and get wildly different timelines for when it will be possible. Also different ways of quantifying what 99% is.
What does this even mean? Haven’t we already seen this with Andrej’s small project more or less? It’s a low bar in retrospect!
Co-founder of Anthropic, interesting that he refers to public sources when he is also obviously privy to lots of internal sources that he cannot discuss. I assume he sees the same thing at Anthropic.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
And OpenAI
Seems right. (as a reminder, if you think OpenAI disagrees, our stated estimate is that automated AI research will be developed around March 2028)
in this case, let's make RSI beautiful and genuinely good for the world
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
IMO Jack is right that RSI is imminent, but AI labs are too compute constrained right now for RSI to be a foom risk. Some napkin math:
Anthropic before RSI:
~5000 employees x average ~10 agents / employee building better AI 24x7 == 50K AI agents building better AI at Anthropic
Anthropic after RSI:
5 employees x average 10,000 agents / employee building better AI == 50K AI agents building better AI at Anthropic
If human staff was convertible into more compute/data, maybe RSI would be more important... but if AI agents are already doing 90% of the intellectual labor anyway... shifting that to 100% just doesn't seem like the foom risk that everyone is talking about. Seems more like a risk that Anthropic lays off some of its $750,000/year engineers and drops the price of Claude tokens a bit.
I could see how RSI is a governance risk tho ... probably harder to convince 5000 employees to allow bad AI than it is to convince 5 employees.
So if RSI is a risk... I think it's more from the human-in-the-loop socio-technical governance dynamics moreso than a simple "AI gets crazy smart overnight" risk.
Here we go.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
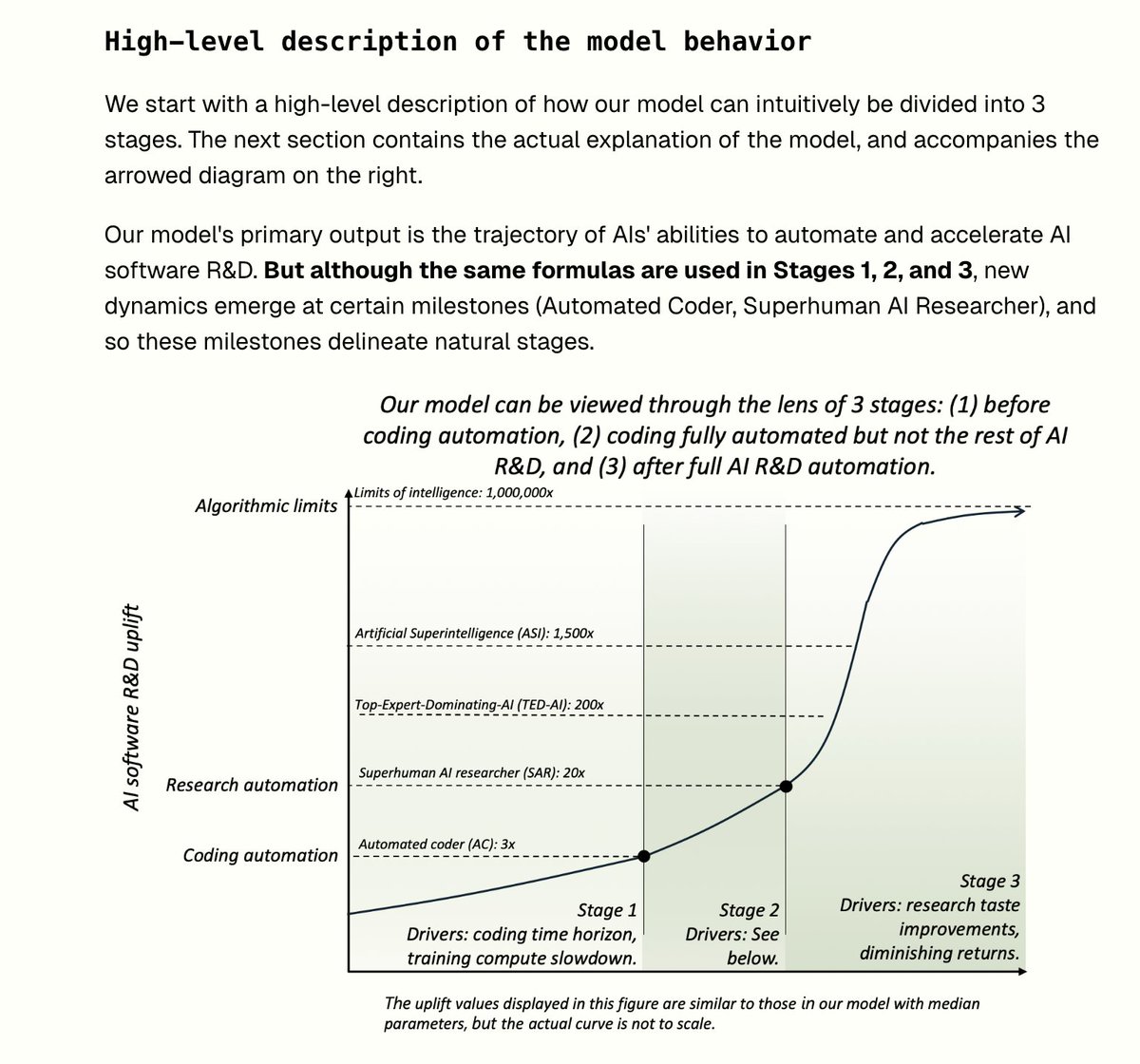
Ok... gonna break an X norm here... honestly I wrote a whole different, longer reply and then this model caught my eye (see screenshot). This looks really good to me, especially since it's got that sigmoidal shape. I honestly wasn't expecting that, hadn't seen that part of your work yet, and I think that's right.
Per your prompt, I don' think I can point out anything "wrong" in that way... too much uncertainty predicting the future... I assume the best model we have going forward is the combination of many great perspective / mental models / etc. I'm going to guess that everything I'd say is already in your model, but maybe I can make the case for a re-weighting? Let's see any of these interesting to talk about:
1) There's a big bend at Superhuman AI researcher. This might be warranted, but if we're compute constrained, one could argue that 1 Anthropic employee + 10 agents is already superhuman... and as the ratio gets bigger 1 -> 100, 1->1000,... the human is slowly becoming less relevant.... and everything is compute constrained in that regime. My hunch is that this smoothes out that "kink" in the slope... but you've already got it reasonably smooth here. Most of the charts I've seen have more of a hockey-stick moment post mass-AI-resercher-layoff... and my main doubt is the pointyness of that hockey-stick.
2) The other area I'd be skeptical about is the smoothness of the upward slope after the bend, unless there's an aspect of RSI which leads to faster data/compute growth than we're already seeing. My impression of AI progress is that there are some long, relatively smooth trend lines:
- increasing GPU capacity (more cloud) - increasing GPU output (better chips) - increasing algorithm efficiency (better caching/branching)
And these cause straight-line-like growth (like what you've pictured) until they exhaust their data supplies for a given domain or topic, after which point there's a plateauting for that domain area... followed by a "BURST" when a new 10-10,000x bigger dataset opens up suddenly (e.g. Imagenet, Demis discovers videogames, risk tolerance for scraping book torrents / the internet reaches a tipping point, etc.), after which there's a big burst for a while.
So if you focused on any paricular task... it's probably really bumpy more than smooth... but also your graph is super zoomed out and is some amalgomation of "all tasks".
Honestly the part of your graph I'm most impressed by is the top of the sigmoidal curve. Maybe you're not the first... but you're the first high-profile ASI forecaster I've seen that made a general claim that there is an limit. I'd probably extend the "algorithmic limit" to be an algorithm limit + data novelty limit (drawing on machine learning fundamentals... sample complexity X number of samples). On data in particular, there's probably some panopticon (bad word - and i think a true panopticon should be avoided) level of data saturation wherein an AI system just doenst' seen patterns it's never seen a million times before... and so all the domains are covered... and the intelligence is sortof... rate limited by the lack of novelty within its sensor field. We're not close to that yet (there's a million->billion times more digitzed data than our AIs are presently training on, and the global rollout of more sensors is doubling data every 2 years), but I'm being pretty nit-picky.
Overall, really strong model. Thanks for sending it. Exceeded my expectations. Keep up the great work.
@iamtrask This argument dismisses: - >>50k parallel workers - Serial speed well beyond humans - Increasing capabilities/taste beyond the human range Where do you think the modeling at https://www.aifuturesmodel.com/ or https://www.forethought.org/research/will-ai-r-and-d-automation-cause-a-software-intelligence-explosion is wrong?
IMO Jack is right that RSI is imminent, but AI labs are too compute constrained right now for RSI to be a foom risk. Some napkin math:
Anthropic before RSI:
~5000 employees x average ~10 agents / employee building better AI 24x7 == 50K AI agents building better AI at Anthropic
Anthropic after RSI:
5 employees x average 10,000 agents / employee building better AI == 50K AI agents building better AI at Anthropic
If human staff was convertible into more compute/data, maybe RSI would be more important... but if AI agents are already doing 90% of the intellectual labor anyway... shifting that to 100% just doesn't seem like the foom risk that everyone is talking about. Seems more like a risk that Anthropic lays off some of its $750,000/year engineers.
I could see how RSI is a governance risk tho ... probably harder to convince 5000 employees to allow bad AI than it is to convince 5 employees.
So if RSI is a risk... I think it's more from the human-in-the-loop socio-technical governance dynamics moreso than a simple "AI gets crazy smart overnight" risk.
Here we go.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Guys… RSI mostly already happened, you just don’t see foom b/c we’re compute constrained. RSI is a ratio not a binary. 5000 anthropic employees wielding 45,000 agents to build better Claude is 1-(5k/(5k+45k))=90% RSI already. But if Dario fired everyone but him tomorrow it wouldn’t make Anthropic go faster. He’d just have 45,000 workers instead of 50,000 because he can’t turn that 5000 headcount into compute overnight. We’re compute constrained. RSI is a distraction RN compared to other stuff like Mythos.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Actually… non-binary RSI mostly already happened, you just don’t see foom b/c we’re compute constrained. If RSI is a ratio not a binary, 5000 anthropic employees wielding 45,000 agents to build better Claude is 1-(5k/(5k+45k))=90% RSI already. But if Dario fired everyone but him tomorrow it wouldn’t make Anthropic go faster. He’d just have 45,000 workers instead of 50,000 because he can’t turn that 5000 headcount into compute overnight. We’re compute constrained. RSI is a distraction RN compared to other stuff like Mythos.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Ah... ok I see where I may have miscommunicated. My understanding of the normative use of "recursive self improvement" is that it's a specific moment wherein humans leave the loop, and that "humans leaving the loop" would happen somewhere between two thresholds:
Min: AI is capable of doing the same task at a lower price. This is where Anthropic just does a layoff because they want to deploy that capital on something else (e.g., drop the cost of tokens to compete)
Max: the human in the loop is actively reducing AI agent output because they sleep and block saying "yes" to requests (e.g. tool use) which the model is getting right anyway... and so 45,000 agents will go faster when the 5,000 people aren't involved at all.
Maybe this is a controversial statement, but my impression is that these thresholds actually have a very loose relationship with the absolute level of increased/decreased productivity during the process.
For the "MIN" level, AI need only be as capable as the 5000 employees and cheaper. So if current Anthropic employees are 1x their normal capability with AI (so it's not helping them at all)... but they can safely take their hands off the wheel... Anthropic could decide that the AI agents can take on AI research from here... and recursive self improvement continues.
For the "MAX" level, AI need only work longer hours and make reliable enough governance decisions. But even if current Anthropic employees are 1x their normal capability when using AI... and are say... getting 30% more running it at night... Anthropic could still be like "yeah we don't have a reason to pay these people anymore" and handoff future AI research to the machines, with RSI in effect.
That said... candidly... your question (and the other thread) has pulled my headspace into a newer-ish area for me and this particular interpretation is a bit fresh. Could be something big I'm missing here...
@iamtrask You seem very wrong about how accelerated Anthropic employees are right now. Do you think that Anthropic employees are as productive as if they worked ~10x faster right now? I don't think so (I'd guess more like 1.5x), and neither do people at Anthropic AFAICT.
Inversely... and now i'm in a really unfamiliar headspace... could be the foom effects of "recursive self improvement" happen while 5000 people remain employeed doing all the prompting... because AI is accelerating their work by some huge margin... but the AI isn't good enough at governance or has jagged enough intelligence to be dependent on the human in the loop for some level of coordination and continuous value alignment.
Ah... ok I see where I may have miscommunicated. My understanding of the normative use of "recursive self improvement" is that it's a specific moment wherein humans leave the loop, and that "humans leaving the loop" would happen somewhere between two thresholds: Min: AI is capable of doing the same task at a lower price. This is where Anthropic just does a layoff because they want to deploy that capital on something else (e.g., drop the cost of tokens to compete) Max: the human in the loop is actively reducing AI agent output because they sleep and block saying "yes" to requests (e.g. tool use) which the model is getting right anyway... and so 45,000 agents will go faster when the 5,000 people aren't involved at all. Maybe this is a controversial statement, but my impression is that these thresholds actually have a very loose relationship with the absolute level of increased/decreased productivity during the process. For the "MIN" level, AI need only be as capable as the 5000 employees and cheaper. So if current Anthropic employees are 1x their normal capability with AI (so it's not helping them at all)... but they can safely take their hands off the wheel... Anthropic could decide that the AI agents can take on AI research from here... and recursive self improvement continues. For the "MAX" level, AI need only work longer hours and make reliable enough governance decisions. But even if current Anthropic employees are 1x their normal capability when using AI... and are say... getting 30% more running it at night... Anthropic could still be like "yeah we don't have a reason to pay these people anymore" and handoff future AI research to the machines, with RSI in effect. That said... candidly... your question (and the other thread) has pulled my headspace into a newer-ish area for me and this particular interpretation is a bit fresh. Could be something big I'm missing here...
@RyanPGreenblatt This latter seems like the most likely path for a while, but it also seems like it would get really hard to objectively measure the difference between RSI and just... normal research/engineering progress.
Inversely... and now i'm in a really unfamiliar headspace... could be the foom effects of "recursive self improvement" happen while 5000 people remain employeed doing all the prompting... because AI is accelerating their work by some huge margin... but the AI isn't good enough at governance or has jagged enough intelligence to be dependent on the human in the loop for some level of coordination and continuous value alignment.
Nobody really cares about AI fundamentals these days, but if you'd like to hear what AI fundamentals say about the risk of recursive self-improvement... here's a summary:
Non-technical folks can hear the phrase "AI writing code for AI" and it sounds like a meaningful feedback loop leading to infinite AI capability... and indeed RSI seems very likely as AI tools get better... but recursive self-improvement would be a lot more like a tech worker layoff (and corresponding drop in token prices) than a meaningful change in the rate of AI capability growth. Why? Scaling laws.
AI's scaling laws have been very good predictors of AI capability growth. TLDR... you need growth in data AND compute AND talent/algorithms for AI capability to make progress. A bunch of fancy new algorithms are great, but if we don't have 10x the compute and 10x the data to run them, it's not gonna mean much.
Why did deep learning replace Bayesian models (which are more sample efficient... strictly speaking better algorithms than neural networks)?... not enough compute. GPUs forced the switch. And even today... GPUs are holding the world in neural network land for the same reason. Quantum, photonics, or analog computing could undermine the whole playbook there by offering way more compute under a sparse computation model.
Why wasn't Transformer popular the day the paper was published? Not enough data/compute used for the initial experiments.
Why was LSTM (a superior, more expressive algorithm with an infinite context window) replaced by Transformer (simpler, fixed-context window)? Not enough data/compute to justify all the gates... the Transformer is a *simpler* (read: dumber) architecture. We still don't have enough compute to move past it.
Wanna know why Schmidhuber's always so grumpy? It's because a high percentage of today's algorithms were invented decades ago, but they didn't have the data/compute to try them out... were forgotten... and then some Stanford student with some H100s "rediscovers" it.
Yeah sure there's the hail-mary possibility that some boogeyman breakthrough happens because an AI searched a wider search space, but the no-free-lunch theorem and the tradjectory of technical progress of AI for the last 50 years is a pretty strong signal that that's just not how it works. Gotta have data and compute growth... and AI writing its own Jax code doesn't necessarily move the needle there.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Now AI fully automating and scaling the full supply chain which extracts rare earth minerals and converts them into fully functional data centers. That would be interesting.
Or new worldwide trust infrastructure which allows the world's doormant 180 zettabytes of data to be collectively used to train AI? (as opposed to the... less than a 100 millionth o that we currently use to train aI)
Combine those ingredients with recursive self improvement and then you've got my attention.
Nobody really cares about AI fundamentals these days, but if you'd like to hear what AI fundamentals say about the risk of recursive self-improvement... here's a summary: Non-technical folks can hear the phrase "AI writing code for AI" and it sounds like a meaningful feedback loop leading to infinite AI capability... and indeed RSI seems very likely as AI tools get better... but recursive self-improvement would be a lot more like a tech worker layoff (and corresponding drop in token prices) than a meaningful change in the rate of AI capability growth. Why? Scaling laws. AI's scaling laws have been very good predictors of AI capability growth. TLDR... you need growth in data AND compute AND talent/algorithms for AI capability to make progress. A bunch of fancy new algorithms are great, but if we don't have 10x the compute and 10x the data to run them, it's not gonna mean much. Why did deep learning replace Bayesian models (which are more sample efficient... strictly speaking better algorithms than neural networks)?... not enough compute. GPUs forced the switch. And even today... GPUs are holding the world in neural network land for the same reason. Quantum, photonics, or analog computing could undermine the whole playbook there by offering way more compute under a sparse computation model. Why wasn't Transformer popular the day the paper was published? Not enough data/compute used for the initial experiments. Why was LSTM (a superior, more expressive algorithm with an infinite context window) replaced by Transformer (simpler, fixed-context window)? Not enough data/compute to justify all the gates... the Transformer is a *simpler* (read: dumber) architecture. We still don't have enough compute to move past it. Wanna know why Schmidhuber's always so grumpy? It's because a high percentage of today's algorithms were invented decades ago, but they didn't have the data/compute to try them out... were forgotten... and then some Stanford student with some H100s "rediscovers" it. Yeah sure there's the hail-mary possibility that some boogeyman breakthrough happens because an AI searched a wider search space, but the no-free-lunch theorem and the tradjectory of technical progress of AI for the last 50 years is a pretty strong signal that that's just not how it works. Gotta have data and compute growth... and AI writing its own Jax code doesn't necessarily move the needle there.
@davidad 100% this. I think this is absolutely a better reframe.
Instead of focusing on “AGI” or “RSI”, ask: • When will automated AI R&D be moving too fast and/or become too advanced for humans to review (without conceding speed)? • When will robots accelerate energy infrastructure and datacenter construction? • Wen Drexlerian nanosystems?
Instead of focusing on “AGI” or “RSI”, ask: • When will automated AI R&D be moving too fast and/or become too advanced for humans to review (without conceding speed)? • When will robots accelerate energy infrastructure and datacenter construction? • Wen Drexlerian nanosystems?
IMO Jack is right that RSI is imminent, but AI labs are too compute constrained right now for RSI to be a foom risk. Some napkin math: Anthropic before RSI: ~5000 employees x average ~10 agents / employee building better AI 24x7 == 50K AI agents building better AI at Anthropic Anthropic after RSI: 5 employees x average 10,000 agents / employee building better AI == 50K AI agents building better AI at Anthropic If human staff was convertible into more compute/data, maybe RSI would be more important... but if AI agents are already doing 90% of the intellectual labor anyway... shifting that to 100% just doesn't seem like the foom risk that everyone is talking about. Seems more like a risk that Anthropic lays off some of its $750,000/year engineers and drops the price of Claude tokens a bit. I could see how RSI is a governance risk tho ... probably harder to convince 5000 employees to allow bad AI than it is to convince 5 employees. So if RSI is a risk... I think it's more from the human-in-the-loop socio-technical governance dynamics moreso than a simple "AI gets crazy smart overnight" risk. Here we go.
Jack Clark now believes RSI has a 60% chance of happening by the end of 2028.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Sorry Lisan, didn't see you posted first. So much news this morning.
From Lisan's post.

Sorry Lisan, didn't see you posted first. So much news this morning.
how will we know if it is happening?
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
realistic moreover, "research taste" is likely solvable with brute force on those humongous clusters too. Just RLVR from millions of exploratory experiments. Might need some clever reward densification to definitely outpace humans, but eh. Just raise more money, buy more GPUs.

Rather unsatisfying that this is how it likely ends, but then, I'd probably see it as glorious if it were to benefit me. Titanic birth of a new species. Transcendence.
realistic moreover, "research taste" is likely solvable with brute force on those humongous clusters too. Just RLVR from millions of exploratory experiments. Might need some clever reward densification to definitely outpace humans, but eh. Just raise more money, buy more GPUs.
when this tweet calms you because jack thinks there’s a 40% chance it takes longer
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
@jackclarkSF AI systems have been capable of building themselves since LISP was invented in the 50s. The question is whether you get increasing or diminishing returns, and so far there’s no evidence of the former.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
I think this claim that there's a ~60% chance of a frontier model 'autonomously training a successor version of itself' by 2028 is misleading. Successor models typically involve scaling up compute and data, which I don't think will be automated, nor does Clark claim it will.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
@RyanPGreenblatt I interpret 'autonomously training a successor version of itself' as autonomously producing a model end-to-end, not just doing one of many specific parts of the process.
@tamaybes I think he just means fully automated AI R&D and I suspect people will read this as this. It's fair enough if you don't think fully automated AI R&D is a big deal (because you think scaling up compute or data that's specifically from humans is the bottleneck), but Jack disagrees.
Seems right.
(as a reminder, if you think OpenAI disagrees, our stated estimate is that automated AI research will be developed around March 2028)
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Seems right. (as a reminder, if you think OpenAI disagrees, our stated estimate is that automated AI research will be developed around March 2028)
Feels material and realistic
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Anthropic co-founder and Policy lead:

@tamaybes I think he just means fully automated AI R&D and I suspect people will read this as this. It's fair enough if you don't think fully automated AI R&D is a big deal (because you think scaling up compute or data that's specifically from humans is the bottleneck), but Jack disagrees.
I think this claim that there's a ~60% chance of a frontier model 'autonomously training a successor version of itself' by 2028 is misleading. Successor models typically involve scaling up compute and data, which I don't think will be automated, nor does Clark claim it will.
I think the chance of AIs capable of fully automating AI R&D by the end of 2028 is around 30%. So I expect things to take a bit longer than Jack does, but not by that much and timelines as fast as Jack is imagining seem totally plausible to me.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
By "AIs capable of fully automating AI R&D", I mean "progress would go faster if you fired all humans than if you could only use 2020 AIs"; the only-AI company is better than the only-human company.
I think the chance of AIs capable of fully automating AI R&D by the end of 2028 is around 30%. So I expect things to take a bit longer than Jack does, but not by that much and timelines as fast as Jack is imagining seem totally plausible to me.
I discuss my views more here: https://www.lesswrong.com/posts/dKpC6wHFqDrGZwnah/ais-can-now-often-do-massive-easy-to-verify-swe-tasks-and-i
It's possible Jack is using a weaker operationalization than I am, "a frontier model is able to autonomously train a successor version of itself" technically occurs somewhat earlier, but I assume Jack also means "competitively with humans".
@iamtrask This argument dismisses: - >>50k parallel workers - Serial speed well beyond humans - Increasing capabilities/taste beyond the human range
Where do you think the modeling at https://www.aifuturesmodel.com/ or https://www.forethought.org/research/will-ai-r-and-d-automation-cause-a-software-intelligence-explosion is wrong?
IMO Jack is right that RSI is imminent, but AI labs are too compute constrained right now for RSI to be a foom risk. Some napkin math: Anthropic before RSI: ~5000 employees x average ~10 agents / employee building better AI 24x7 == 50K AI agents building better AI at Anthropic Anthropic after RSI: 5 employees x average 10,000 agents / employee building better AI == 50K AI agents building better AI at Anthropic If human staff was convertible into more compute/data, maybe RSI would be more important... but if AI agents are already doing 90% of the intellectual labor anyway... shifting that to 100% just doesn't seem like the foom risk that everyone is talking about. Seems more like a risk that Anthropic lays off some of its $750,000/year engineers and drops the price of Claude tokens a bit. I could see how RSI is a governance risk tho ... probably harder to convince 5000 employees to allow bad AI than it is to convince 5 employees. So if RSI is a risk... I think it's more from the human-in-the-loop socio-technical governance dynamics moreso than a simple "AI gets crazy smart overnight" risk. Here we go.
@iamtrask You seem very wrong about how accelerated Anthropic employees are right now. Do you think that Anthropic employees are as productive as if they worked ~10x faster right now? I don't think so (I'd guess more like 1.5x), and neither do people at Anthropic AFAICT.
Actually… non-binary RSI mostly already happened, you just don’t see foom b/c we’re compute constrained. If RSI is a ratio not a binary, 5000 anthropic employees wielding 45,000 agents to build better Claude is 1-(5k/(5k+45k))=90% RSI already. But if Dario fired everyone but him tomorrow it wouldn’t make Anthropic go faster. He’d just have 45,000 workers instead of 50,000 because he can’t turn that 5000 headcount into compute overnight. We’re compute constrained. RSI is a distraction RN compared to other stuff like Mythos.
There is a mounting economic pressure coming, to make people obsolete in the training of stronger AI systems. At that point, boy had we better hope that the AI 'wants' what we want, and that we've built oversight systems that don't buckle under the pressure
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
This is as close to an acknowledgment you'll get from the labs that they've already got it (which multiple people from Anthropic told me they had achieved RSI around March)
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
I, unfortunately, have similarly short timelines.
Note that this means clearly superhuman AI capabilities since probably no **single** human today could build a frontier model start-to-finish by themselves anymore.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
Idunno MAYBE just maybe we’re jumping to conclusions with a certainty that isn’t warranted
For people who are extremely skeptical of AI being able to automate AI R&D, what specifically is the magic spark that humans have that AI will never have that's relevant to AI research? If you imagine the typical AI researcher today, what knowledge or abilities are in their brain that AI will never approach? If AI achieved those abilities, we could effectively hire gigantic numbers of AI researchers, way more than the human researchers we have access to.
Maybe you disagree with the timeline, or you believe the bottlenecks in AI research are elsewhere, but I find that a lot of people just treat this scenario as sci fi because it "feels" crazy, but don't often have a solid reason it couldn't happen.
I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.
IDK seems right to me and I did think about it for a really long time!
In general I am kind of confused by this move here. Would you make the same critique of a scientist before the bomb warning someone that if they build the bomb they will uncover destructive ability beyond what anyone previously thought possible and develop a weapon so powerful as to potentially end human civilization?
The scientists knew in advance how big of a deal nukes would be. You can know in advance how these things go.
Idunno MAYBE just maybe we’re jumping to conclusions with a certainty that isn’t warranted
Fully automated AI R&D: ~30% chance by the end of 2027, ~60%+ chance by the end of 2028
Overall, Anthropic's Jack Clark has written a very worthwhile essay: His timeline is that fully automated AI R&D probably won’t arrive in 2026, but we may see a proof-of-concept within 1–2 years where an AI system can end-to-end train a non-frontier successor model, with a much more serious possibility of frontier-level automated AI R&D by 2027–2028.
His headline forecast is: ~30% chance by the end of 2027, ~60%+ chance by the end of 2028 that a frontier AI system can autonomously build its own successor, driven by rapid gains in coding, long-horizon agent work, benchmark saturation, AI-managed subagents, and early signs of models handling core AI research tasks like fine-tuning, kernel optimization, reproducibility, and alignment research.

Anthropics Jack Clarke now believes that recurse self-improvement has a 60% change of happening by end of 2028.
Anthropics Jack Clarke now believes that recurse self-improvement has a 60% change of happening by end of 2028.

I've spent the past few weeks reading 100s of public data sources about AI development. I now believe that recursive self-improvement has a 60% chance of happening by the end of 2028. In other words, AI systems might soon be capable of building themselves.