METR evaluates Anthropic Claude Mythos Preview at 16-hour risk horizon
——0——
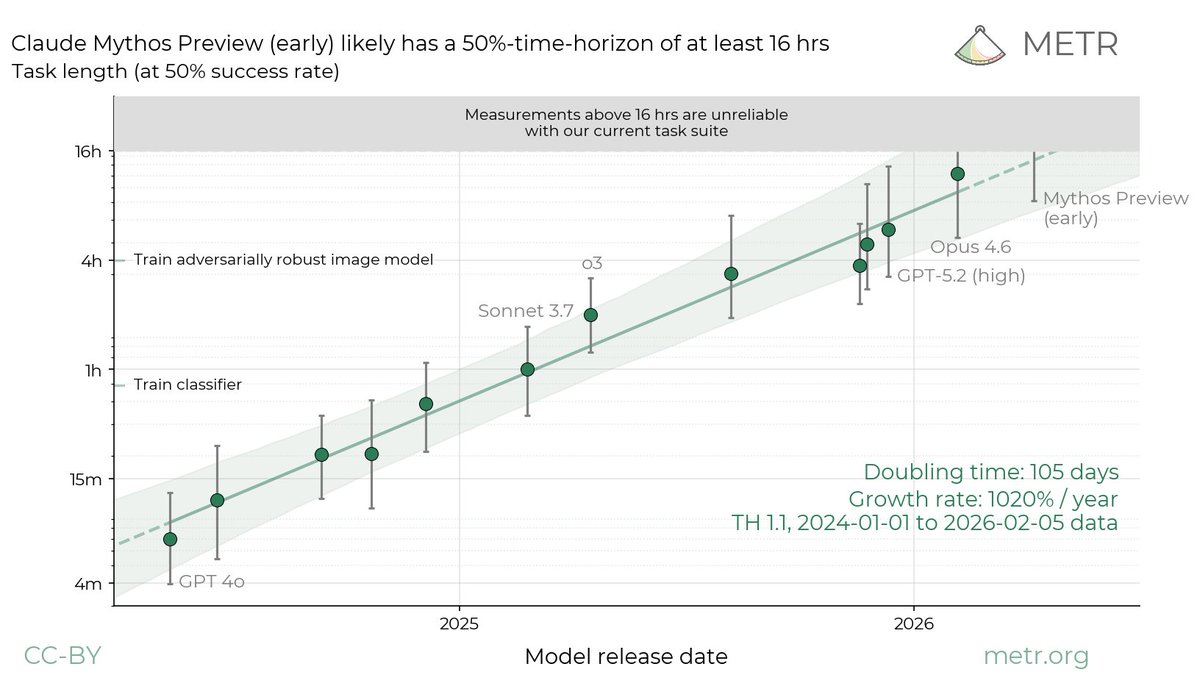
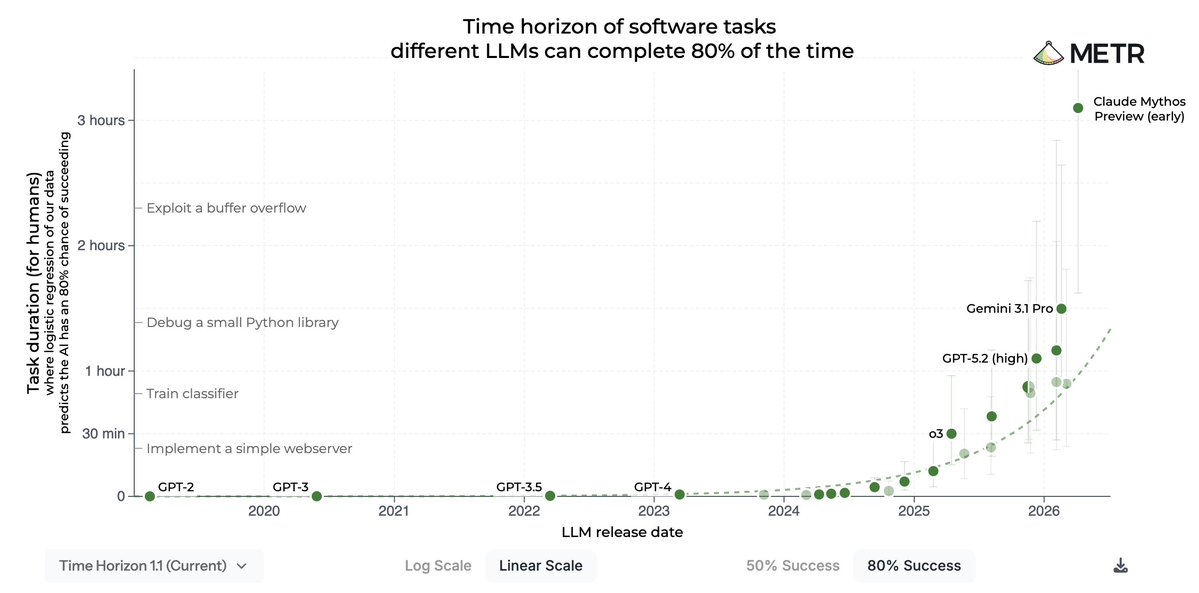
METR evaluated early Anthropic Claude Mythos Preview in March 2026, estimating 50% time horizon of at least 16 hours (95% CI: 8.5–55 hours) on risk-assessment tasks. The model more than doubled the time horizon of the next-best system on METR’s 80% success-rate benchmark, hitting the upper limit of current measurement capabilities using standard software engineering and agentic tasks.
AI 1000 · 21 actions
- POSTME#45@METR_EVALSWe evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks. https://x.com/METR_Evals/status/2052896621760004602/photo/1
- QUOTEGM#143@GARYMARCUS@METR_EVALSHot take on METR’s new graph that so many people are flipping about today. • Claude Code is a real advance; Mythos probably builds on some of what is learned there. But… • If you read the graph carefully, it is about achieving *50%* success. Not 100 or 99 or even 90. The key problem with GenAI has been reliability; this graph does not address reliable performance. At all. • If you read carefully, it is only about software tasks. Not general intelligence. • It certainly doesn’t tell you that *most* (let alone) all things that humans can do in 16 hours can be done in Mythos, let alone reliably • Aside from this, the graph doesn’t show you *how* the improvements have been made. As noted in my newsletter a lot of the advance in recent months is likely from the incorporation of symbolic tools (like code interpreters, verification, and harnesses) rather than from model scaling per se. As such this a vindication of neurosymbolic AI – but not a proof that LLMs themselves can be perpetually scaled. As such it’s not a proof that another trillion dollars will continue the graph. • Per @ramez, Mythos is not actually off trend on the ECI benchmark, which is a broader measure.
- QUOTEGM#143@GARYMARCUS@PETERWILDEFORDSorry, @peterwildeford, but this is wrong. Please don’t play along. The measurement “wall” you mention is hit ONLY if you don’t insist on reliability. If you demanded 95% accuracy on the task, the systems wouldn’t be close to the measurement wall. The measurement problem you allude to is an artifact of artificially lowered expectations.
- REPOSTAC#288@AJEYA_COTRA@METR_EVALSWe evaluated an early version of Claude Mythos Preview for risk assessment during a limited window in March 2026. We estimated a 50%-time-horizon of at least 16hrs (95% CI 8.5hrs to 55hrs) on our task suite, at the upper end of what we can measure without new tasks. https://x.com/METR_Evals/status/2052896621760004602/photo/1