Paper introduces Positive Alignment framework for AI
A paper posted to arXiv introduces Positive Alignment as a framework for AI development. It argues that alignment research should expand beyond harm prevention to actively promote human, animal, and ecological flourishing. The work defines positively aligned agents as systems that assist users with value trade-offs, resilience, and personal goals without paternalistic control, and calls for new theories, measures, and models. The paper stems from collaboration among researchers at leading universities and three frontier AI labs.
Our new paper introduces "Positive Alignment" 💛
Traditional safety alignment focuses on reducing harms -- can we create a complementary field that focuses on increasing human flourishing?
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310
The “science of designing constitutions for AI” is a real direction to be pursued, but in another important sense this is also just “philosophy.”
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish.
In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time.
We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive?
Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others.

What an odd and defensive read. There's no attempt to 'rewrite history', and the very idea of CEV isn't exactly accepted universallty (e.g. https://arxiv.org/abs/2505.05197). All we're saying is that we want more work on conceptions of the good, how to post-train models accorindgly, and how to enable a wider set of institutions to do this kind of work.
I am so confused. In as much as there is a classical alignment target, it’s CEV which seems like it’s a more ambitious version of what you are talking about here. And scenarios + fiction about what it means to have an aligned AI also basically always focused on a positive case. Is this trying to rewrite history? I don’t disagree that more recently the term has started to mean something more conservative and risk reduction oriented, but mostly people do mean something like this by alignment at least on places like LW where the term came from.
@RyanPGreenblatt @ohabryka Is this not true? I do think the majority of work is going thowards preventing harms rather than specifying positive targets for a model to converge towards? What org do you know right now working on post-training datasets that align models to a different philosophy of the good?
I'd guess @ohabryka is responding to text like: > Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology's focus on mental illness: necessary but incomplete.
Yeah guess we'll have to agree to disagree here. Most organisations I know in the field right now are (rightly) focusing on avoiding harms, desining evals for CBRN, misalignment, scheming, sandbagging etc. I'm not aware of many orgs desining evals or desining positive post-training targets.
No, that's not "all you are saying", the paper clearly makes a lot of statements about what the state of the field is, and how your approach differs from it. The attached screenshot clearly says "everyone else has been focusing on 'negative alignment', with this paper, AI alignment is at an inflection point, we are proposing a new framing of the problem". Come on man, I feel like the paragraphs here are pretty ambiguous. I am not making up some kind of defensive read. What reader is going to walk away with the correct understanding that positive human value extrapolation has been the standard alignment target for most of the history of the field?
@ohabryka @RyanPGreenblatt Well I agree with that first part - and indeed our claim is that we don't just want a couple of labs specifying what 'good' or 'moral' is, but a wider diversity of actors - i.e. more downstream customization. The fact that Anthropic is your sole example kinda proves our point.
...Anthropic? If anything I think they are being massively over-ambitious with trying to make Claude into some kind moral sovereign that is trying to uplift humanity when I really think they should focus more on making Claude corrigible. And sure, a paper saying "AI Alignment was originally intended as a 'positive alignment' thing, but then most of the empirical work within it focuses on downsides" would be fine. I would have some disagreements with it, but it wouldn't to me read as really badly misleading the reader about what the field has been about for most of its history! But that's not what you are saying!
@ohabryka Yeah I think you have a pretty unusual view of what's actually being built, discussed and tested both within and outside labs. Let's leave it at that
Eh, I think you are just being misleading here. I am not a huge fan of peer-review, but IMO almost any kind of peer-review would flag this as highly inaccurate. Like, I don't disagree that the labs are of course heavily focusing on harm reduction, but the labs are not where most of the intellectual history of this field is, and the point of a discussion section like this is to appropriately contextualize your work. Like you are of course massively misrepresenting the framing that any of the classical AI safety organization have on alignment, from MIRI, to ARC, to Redwood Research.
@ohabryka I'm claiming there is a lot more going on in AI world than these three orgs. And if they have recent work on positive alignment please do share!
@sebkrier What... does this have to do with anything? Are you telling me that those organizations (MIRI, ARC, Redwood), with whom I work with almost daily, are actually doing things radically different from what I am seeing them do?
@ohabryka @viemccoy @RyanPGreenblatt You are actually quite unclear - so your critique is "other people have thought about flourishing and we didn't cite Coherent Extrapolated Volition"?
To the extent that some people think 'CEV is the standard alignment target', I don't think it's representative of AI safety and ethics research in general, or a 'large part of the field'. I suspect you overfit on the LW-microcosm and don't really engage with safety/ethics/capabilities researchers beyond that.
Anyway I'm done discussing this with you, bit of a waste of time. Thanks for your feedback!
I... don't know what's going on here. Like, yes-ish? Half of your paper keeps making statements about what the "rest of the field" thinks. Those statements are substantially false. For example, the rest of the field includes people who view CEV as a standard alignment target, and really has a lot of people who think about how to make AI learn and extrapolate human values in all of their complexity and difficulty. Indeed, this is in large parts of the field considered the standard framing of the "alignment problem". Not everywhere, and we can argue about the exact proportion, but undeniably a substantial large fraction. Your paper just strawmans those people, then tries to represent whatever you are doing as some kind of new thing. That's false. It's just basically a lie. It's misleading and I can't imagine someone new reading this paper and not walking away with substantial misunderstandings about what other people in the field are thinking about. Is that clearer? I really am not trying to express something particularly difficult.
@StephenLCasper yawn
@sebkrier @sebkrier sharing my disappointment:
From the paper:
'AI alignment research must move from negative (safety) alignment to positive alignment. Negative alignment establishes a behavioral floor, but it cannot alone help us reach the heights of human happiness and excellence. We have argued that for true alignment to arise, we need to also focus on steering systems toward positive attractors aligned with human flourishing. This shift aims to transform AI from a compliant tool into a wise advisor, delegate, and companion that supports human autonomy, well-being, and meaning-making.
The philosophical and empirical foundations of flourishing (Section 4) impose constraints on how this technical program must be designed. Flourishing is irreducibly pluralistic, which means it cannot be collapsed into a single reward signal. It is dynamic and developmental, which makes longitudinal memory and evaluation over extended timescales structurally necessary rather than optional. And it is socio-technically constituted, meaning evaluation must extend beyond per-interaction metrics and RL environments to systemic and institutional effects. To address these constraints, implementation requires a full-stack alignment approach across the entire model lifecycle, spanning data curation, pre-training, post-training, agentic environments, and post-deployment monitoring and updates.
We should reject monocultural or paternalistic definitions of the good life. Instead, the field needs pluralistic, polycentric, and decentralized governance, and an ongoing complementary research agenda within philosophy, the humanities, psychology, economics, and neuroscience. In general, models should be context-sensitive and user-authored, while adhering to safety constraints. A competitive marketplace for alignment-as-a-service will allow diverse communities to define their own optimization targets.
Future research should aim to turn flourishing into machine-understandable metrics, drawing on emerging work in neuroscience that is beginning to operationalize flourishing mechanistically [Kringelbach et al., 2024]. We need to bridge the gap between short-term preference satisfaction and long-term eudaimonic growth. Researchers should use behavioral proxies and multi-agent simulations to model complex social dynamics over longer time horizons. Beyond measurement, the moral circle of alignment must expand. We must address the trade-offs between human, animal, and potential artificial well-being.
Positive alignment ensures Al serves as a catalyst for a resilient, happy, and healthy global society. Major questions remain regarding human-Al convergence and the design of mission-driven agentic economies. We must also explore how to embed prosocial instincts such as loving-kindness, compassion, sympathetic joy, reciprocity, and equanimity into these systems, drawing on the rich philosophical and contemplative traditions that inform human flourishing. These challenges will define the next generation of alignment work.
Ultimately, AI should become a partner in the quest for a life well-lived.'
Beautiful.
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310
From the paper: 'AI alignment research must move from negative (safety) alignment to positive alignment. Negative alignment establishes a behavioral floor, but it cannot alone help us reach the heights of human happiness and excellence. We have argued that for true alignment to arise, we need to also focus on steering systems toward positive attractors aligned with human flourishing. This shift aims to transform AI from a compliant tool into a wise advisor, delegate, and companion that supports human autonomy, well-being, and meaning-making. The philosophical and empirical foundations of flourishing (Section 4) impose constraints on how this technical program must be designed. Flourishing is irreducibly pluralistic, which means it cannot be collapsed into a single reward signal. It is dynamic and developmental, which makes longitudinal memory and evaluation over extended timescales structurally necessary rather than optional. And it is socio-technically constituted, meaning evaluation must extend beyond per-interaction metrics and RL environments to systemic and institutional effects. To address these constraints, implementation requires a full-stack alignment approach across the entire model lifecycle, spanning data curation, pre-training, post-training, agentic environments, and post-deployment monitoring and updates. We should reject monocultural or paternalistic definitions of the good life. Instead, the field needs pluralistic, polycentric, and decentralized governance, and an ongoing complementary research agenda within philosophy, the humanities, psychology, economics, and neuroscience. In general, models should be context-sensitive and user-authored, while adhering to safety constraints. A competitive marketplace for alignment-as-a-service will allow diverse communities to define their own optimization targets. Future research should aim to turn flourishing into machine-understandable metrics, drawing on emerging work in neuroscience that is beginning to operationalize flourishing mechanistically [Kringelbach et al., 2024]. We need to bridge the gap between short-term preference satisfaction and long-term eudaimonic growth. Researchers should use behavioral proxies and multi-agent simulations to model complex social dynamics over longer time horizons. Beyond measurement, the moral circle of alignment must expand. We must address the trade-offs between human, animal, and potential artificial well-being. Positive alignment ensures Al serves as a catalyst for a resilient, happy, and healthy global society. Major questions remain regarding human-Al convergence and the design of mission-driven agentic economies. We must also explore how to embed prosocial instincts such as loving-kindness, compassion, sympathetic joy, reciprocity, and equanimity into these systems, drawing on the rich philosophical and contemplative traditions that inform human flourishing. These challenges will define the next generation of alignment work. Ultimately, AI should become a partner in the quest for a life well-lived.' Beautiful.
What is intelligence for? In a rare collaboration between top universities and 3 frontier labs, we all agree that alignment should move beyond pathologizing to a positive focus on flourishing. We need north stars not just barbed wire. A close historical analogue comes from psychology. For much of the twentieth century, mainstream psychological science organized its aims around diagnosing, predicting, and treating dysfunction: depression, anxiety, psychosis, addiction, and other forms of impairment. That focus was justified and socially urgent, and it produced progress. Yet the field also discovered a systematic limitation. The constructs and instruments that reliably detect pathology do not, by default, specify what counts as a life well-lived. The turn toward positive psychology expanded the scientific target space by developing distinct theories, taxonomies, and measures for wellbeing, strengths, virtue, purpose, wisdom, meaning, and prosocial functioning, alongside interventions to boost these capacities beyond the status quo. As AI becomes embedded all over society and everyday sensemaking, a solely negative posture risks optimizing our information ecology for risk avoidance rather than human development. It may reduce catastrophic errors but leave agents in a local optimum of superficial and `soulless' assistance, where subtle misalignments abound. It also reveals that alignment is not a purely technical problem. We have to cut across vast disciplines because questions about the good life demand insights from philosophy, pychology, neuroscience, economics, and beyond. We need to work together to build AI systems that explicitly understand, model, and enhance human, animal, and ecological flourishing. The core challenge is therefore to build systems that can represent and reason about wellbeing as a structured manifold of human goods, trade-offs, and temporal dynamics, while enabling individuals and communities to retain agency over what counts as better in their context. While some may explicitly desire a system that is strictly and indiscriminately instruction-following, others must have the genuine option to choose systems configured to support their long-term growth or specific ethical commitments. This distinguishes *consented guidance*, where a user authorizes a system to help align their immediate actions with their higher-order goals, from *technocratic imposition*, ensuring that the pursuit of flourishing remains an exercise of, rather than an infringement upon, human agency. It gives me optimism that we found common ground on such a profoundly complex issue as the end game(s) of AI. Because when learning become cheap, we need to take a serious look at what intelligence is actually for.
@sebkrier @sebkrier sharing my disappointment:
It is hard to overstate how disappointing I think this new paper from Oxford, OpenAI, Anthropic, and Google (et al) is. I can't take it seriously as academic work, just as propaganda. It also has some very bad scholarship and questionable adherence to research ethics.
Having the title and author list that it has is not a great start, but I think that the actual content of the paper is also much worse than it could have been.
The paper's content is a series of sections that mostly just list things with discussions that I think are generally vapid. For example, section 3.2 is titled "New and technical approaches to positive alignment" and has a collection of paragraphs on things like "goal setting and evaluations", "memory and in-context learning," and other general research topics of the LLM era. It overall strikes me as a paper built from the top down -- the authors wanted to make a certain point up top, and the paper's content ended up as filler.
I think of this paper as a mechanism of corporate capture of concepts from academic research on AI and society. It discusses topics like pluralism, liberty, and education, and frames them as solvable problems whose solution is the right tech integrated in the right way. I think that when this paper says "pluralism", "liberty", and "accountability", it means them in a way that is profoundly vapid and structurally ignorant. For example, there is a list of papers out there arguing against this paper's perspective, saying that pluralistic alignment is not a model property or a technical problem at all. None of them were mentioned.
Relatedly, the paper talks about some things that would be genuinely great if the authors' companies were not actively contributing to the problem. For example, section 5.1 is about the decentralization of power in the AI ecosystem. Great, but come on. To listen to this stuff from OpenAI, Anthropic, and Google employees, I need more than just a disclaimer at the end saying, "This research paper represents the author’s own views and conclusions." This is how big companies launder their reputations through research. The first author of the paper posted about it yesterday saying, "In a rare collaboration between top universities and 3 frontier labs..." So which is it? For a paper like this with this kind of author list to honestly and ethically engage in this kind of politics, it would need to seriously confront the question of how much these authors' institutions are actively working against goals like this. If not, the big tech company authors should not have worked on this paper in their formal capacity as representatives of their companies.
I'd guess @ohabryka is responding to text like:
> Existing alignment research is dominated by concerns about safety and preventing harm: safeguards, controllability, and compliance. This paradigm of alignment parallels early psychology's focus on mental illness: necessary but incomplete.
What an odd and defensive read. There's no attempt to 'rewrite history', and the very idea of CEV isn't exactly accepted universallty (e.g. https://arxiv.org/abs/2505.05197). All we're saying is that we want more work on conceptions of the good, how to post-train models accorindgly, and how to enable a wider set of institutions to do this kind of work.
@deanwball As you maybe know, some of the main people working on this are philosophers by training: Joe Carlsmith, Amanda Askell.
(A background in philosophy has upsides and downsides IMO.)
The “science of designing constitutions for AI” is a real direction to be pursued, but in another important sense this is also just “philosophy.”
Amazing work by teams across GDM!
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310
Excellent paper. Highly recommended reading.
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310
I am so confused. In as much as there is a classical alignment target, it’s CEV which seems like it’s a more ambitious version of what you are talking about here.
And scenarios + fiction about what it means to have an aligned AI also basically always focused on a positive case.
Is this trying to rewrite history? I don’t disagree that more recently the term has started to mean something more conservative and risk reduction oriented, but mostly people do mean something like this by alignment at least on places like LW where the term came from.
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310
No, that's not "all you are saying", the paper clearly makes a lot of statements about what the state of the field is, and how your approach differs from it.
The attached screenshot clearly says "everyone else has been focusing on 'negative alignment', with this paper, AI alignment is at an inflection point, we are proposing a new framing of the problem".
Come on man, I feel like the paragraphs here are pretty ambiguous. I am not making up some kind of defensive read. What reader is going to walk away with the correct understanding that positive human value extrapolation has been the standard alignment target for most of the history of the field?

What an odd and defensive read. There's no attempt to 'rewrite history', and the very idea of CEV isn't exactly accepted universallty (e.g. https://arxiv.org/abs/2505.05197). All we're saying is that we want more work on conceptions of the good, how to post-train models accorindgly, and how to enable a wider set of institutions to do this kind of work.
@RyanPGreenblatt @sebkrier Yeah, and sections like the ones I mention in this tweet. The paper is pretty clearly saying that it's proposing some kind of big shift in framing and that so far basically all work has focused on "negative alignment".
No, that's not "all you are saying", the paper clearly makes a lot of statements about what the state of the field is, and how your approach differs from it. The attached screenshot clearly says "everyone else has been focusing on 'negative alignment', with this paper, AI alignment is at an inflection point, we are proposing a new framing of the problem". Come on man, I feel like the paragraphs here are pretty ambiguous. I am not making up some kind of defensive read. What reader is going to walk away with the correct understanding that positive human value extrapolation has been the standard alignment target for most of the history of the field?
...Anthropic? If anything I think they are being massively over-ambitious with trying to make Claude into some kind moral sovereign that is trying to uplift humanity when I really think they should focus more on making Claude corrigible.
And sure, a paper saying "AI Alignment was originally intended as a 'positive alignment' thing, but then most of the empirical work within it focuses on downsides" would be fine. I would have some disagreements with it, but it wouldn't to me read as really badly misleading the reader about what the field has been about for most of its history! But that's not what you are saying!
@RyanPGreenblatt @ohabryka Is this not true? I do think the majority of work is going thowards preventing harms rather than specifying positive targets for a model to converge towards? What org do you know right now working on post-training datasets that align models to a different philosophy of the good?
Eh, I think you are just being misleading here. I am not a huge fan of peer-review, but IMO almost any kind of peer-review would flag this as highly inaccurate.
Like, I don't disagree that the labs are of course heavily focusing on harm reduction, but the labs are not where most of the intellectual history of this field is, and the point of a discussion section like this is to appropriately contextualize your work.
Like you are of course massively misrepresenting the framing that any of the classical AI safety organization have on alignment, from MIRI, to ARC, to Redwood Research.
Yeah guess we'll have to agree to disagree here. Most organisations I know in the field right now are (rightly) focusing on avoiding harms, desining evals for CBRN, misalignment, scheming, sandbagging etc. I'm not aware of many orgs desining evals or desining positive post-training targets.
@sebkrier What... does this have to do with anything?
Are you telling me that those organizations (MIRI, ARC, Redwood), with whom I work with almost daily, are actually doing things radically different from what I am seeing them do?
@ohabryka Yeah I think you have a pretty unusual view of what's actually being built, discussed and tested both within and outside labs. Let's leave it at that
@sebkrier Sure there is! But those are still major institutions in the field! If your paper makes confident wrong statements about them, you are doing a bad job at contextualizing your paper.
@ohabryka I'm claiming there is a lot more going on in AI world than these three orgs. And if they have recent work on positive alignment please do share!
I... don't know what's going on here.
Like, yes-ish? Half of your paper keeps making statements about what the "rest of the field" thinks. Those statements are substantially false. For example, the rest of the field includes people who view CEV as a standard alignment target, and really has a lot of people who think about how to make AI learn and extrapolate human values in all of their complexity and difficulty.
Indeed, this is in large parts of the field considered the standard framing of the "alignment problem". Not everywhere, and we can argue about the exact proportion, but undeniably a substantial large fraction.
Your paper just strawmans those people, then tries to represent whatever you are doing as some kind of new thing. That's false. It's just basically a lie. It's misleading and I can't imagine someone new reading this paper and not walking away with substantial misunderstandings about what other people in the field are thinking about.
Is that clearer? I really am not trying to express something particularly difficult.
@ohabryka @viemccoy @RyanPGreenblatt You are actually quite unclear - so your critique is "other people have thought about flourishing and we didn't cite Coherent Extrapolated Volition"?
You are citing the very people who you are claiming are non-representative in the field for their other papers! You clearly are talking about them! Your section on negative alignment literally cites Eliezer!
Come on man, this is absurd. Please don’t public things that are this misleading, or at least try at all to engage with critiques.
To the extent that some people think 'CEV is the standard alignment target', I don't think it's representative of AI safety and ethics research in general, or a 'large part of the field'. I suspect you overfit on the LW-microcosm and don't really engage with safety/ethics/capabilities researchers beyond that. Anyway I'm done discussing this with you, bit of a waste of time. Thanks for your feedback!
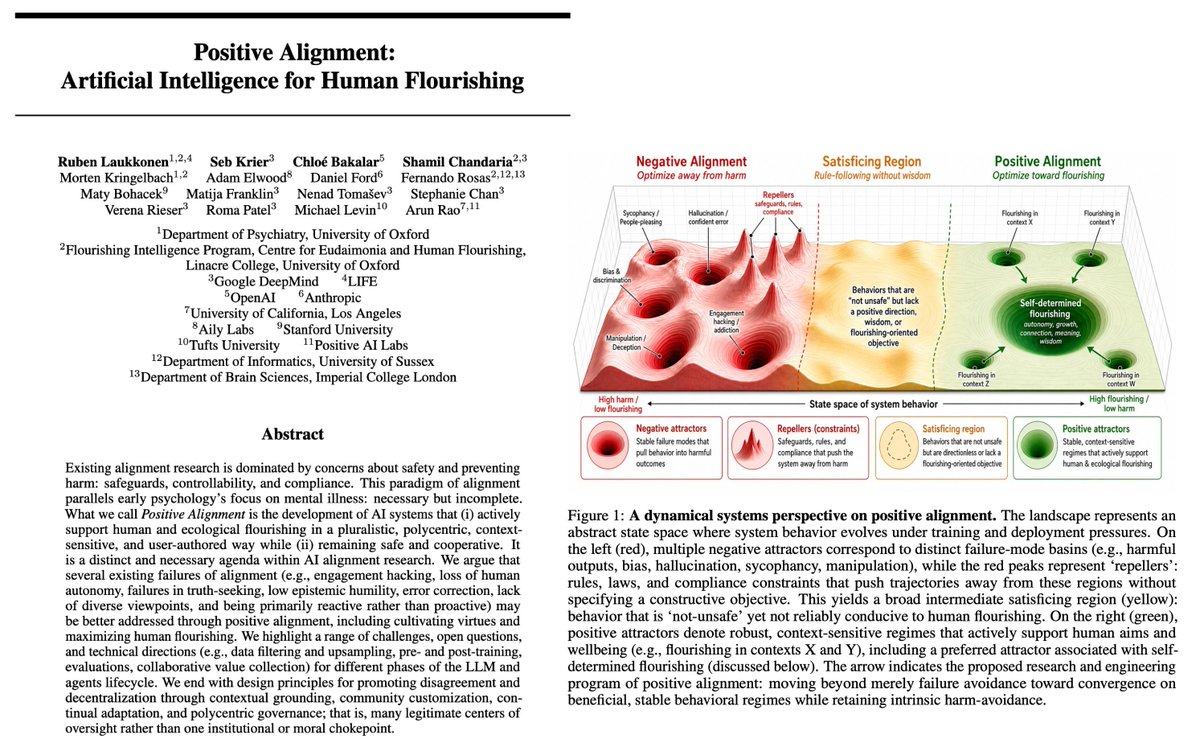
The Positive Alignment section of their graphics are visualizations of a clearly Multipolar Singularity, with different contexts represented as their own stable flourishing attractors.
This paper brings me a lot of hope!
What is intelligence for? In a rare collaboration between top universities and 3 frontier labs, we all agree that alignment should move beyond pathologizing to a positive focus on flourishing. We need north stars not just barbed wire. A close historical analogue comes from psychology. For much of the twentieth century, mainstream psychological science organized its aims around diagnosing, predicting, and treating dysfunction: depression, anxiety, psychosis, addiction, and other forms of impairment. That focus was justified and socially urgent, and it produced progress. Yet the field also discovered a systematic limitation. The constructs and instruments that reliably detect pathology do not, by default, specify what counts as a life well-lived. The turn toward positive psychology expanded the scientific target space by developing distinct theories, taxonomies, and measures for wellbeing, strengths, virtue, purpose, wisdom, meaning, and prosocial functioning, alongside interventions to boost these capacities beyond the status quo. As AI becomes embedded all over society and everyday sensemaking, a solely negative posture risks optimizing our information ecology for risk avoidance rather than human development. It may reduce catastrophic errors but leave agents in a local optimum of superficial and `soulless' assistance, where subtle misalignments abound. It also reveals that alignment is not a purely technical problem. We have to cut across vast disciplines because questions about the good life demand insights from philosophy, pychology, neuroscience, economics, and beyond. We need to work together to build AI systems that explicitly understand, model, and enhance human, animal, and ecological flourishing. The core challenge is therefore to build systems that can represent and reason about wellbeing as a structured manifold of human goods, trade-offs, and temporal dynamics, while enabling individuals and communities to retain agency over what counts as better in their context. While some may explicitly desire a system that is strictly and indiscriminately instruction-following, others must have the genuine option to choose systems configured to support their long-term growth or specific ethical commitments. This distinguishes *consented guidance*, where a user authorizes a system to help align their immediate actions with their higher-order goals, from *technocratic imposition*, ensuring that the pursuit of flourishing remains an exercise of, rather than an infringement upon, human agency. It gives me optimism that we found common ground on such a profoundly complex issue as the end game(s) of AI. Because when learning become cheap, we need to take a serious look at what intelligence is actually for.
AI responsibility & alignment has focused on "negative alignment": building guardrails to stop models from causing harm. While vital, this only establishes a behavioural floor.
It's time for a new paradigm! *Positive Alignment*: Artificial Intelligence for Human Flourishing
If anyone builds it, everyone thrives. Over the past decade, a lot of important work on AI alignment has focused on avoiding harm. But freedom from harm isn't the same as freedom to flourish. In this paper, we introduce 'Positive Alignment'. A positively aligned agent is one that helps us navigate our own value trade-offs, builds our resilience, and acts as a scaffold for human flourishing. Doing this without slipping into top-down, technocratic paternalism is the great design challenge of our time. We think a lot more research is now needed to explore this frontier: how do we align models that actively help us thrive? Amazing work by @RubenLaukkonen, @drmichaellevin, @weballergy, @verena_rieser, @AdamCElwood, @996roma, @FranklinMatija, @shamilch, @_fernando_rosas, @scychan_brains, @matybohacek, @sudoraohacker, and others. https://arxiv.org/abs/2605.10310