PrimeIntellect introduces Renderers boosting RL throughput over 3x
PrimeIntellect introduced Renderers to resolve mismatches in reinforcement learning pipelines where trainers operate on tokens while environments generate messages. The system enforces explicit token-in and token-out handling with user-controlled templating. LMSYS Org collaborated on the effort. The change eliminates hidden chat-template rewrites and delivers more than 3x throughput gains on popular open models.
The jinja chat template has always felt like a temporary equilibrium, so we've needed someone to take the reigns and try to build that out within the community.
Excited about this!
Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.
Harmony was the first attempt at this imo, but it never broke out of the OpenAI model ecosystem. I'm honestly not sure why, but would guess lack of community effort https://github.com/openai/harmony
The jinja chat template has always felt like a temporary equilibrium, so we've needed someone to take the reigns and try to build that out within the community. Excited about this!
@willccbb @vllm_project @sgl_project @huggingface @tinkerapi confirmado

all chat templates are wrong, some chat templates are useful we found some CRAZY performance wins by patching official templates, and we're shipping them in a standalone library you can use with any RL stack w/ examples for @vllm_project @sgl_project @huggingface @tinkerapi
@willccbb @vllm_project @sgl_project @huggingface @tinkerapi src https://rlhfbook.com/teach/course/lec2-chap4-5-9/#14
@willccbb @vllm_project @sgl_project @huggingface @tinkerapi confirmado
A gift from the Gods. Dealing with multiple models and many envs in the same RL codebase while respecting correctness constraints (no train / inference tokenization mismatch) is becoming a huge pain.
I have a vibe-coded draft PR that does exactly this, but happy I won’t have to land or maintain it now. Let’s hope the field can really standardize on one abstraction.
Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.
@TacoCohen Very cool! I think tinker from @thinkymachines had that API as well
A gift from the Gods. Dealing with multiple models and many envs in the same RL codebase while respecting correctness constraints (no train / inference tokenization mismatch) is becoming a huge pain. I have a vibe-coded draft PR that does exactly this, but happy I won’t have to land or maintain it now. Let’s hope the field can really standardize on one abstraction.
@TacoCohen @hallerite @thinkymachines https://github.com/thinking-machines-lab/tinker-cookbook/tree/main/tinker_cookbook/renderers
http://base.py has the ABCs
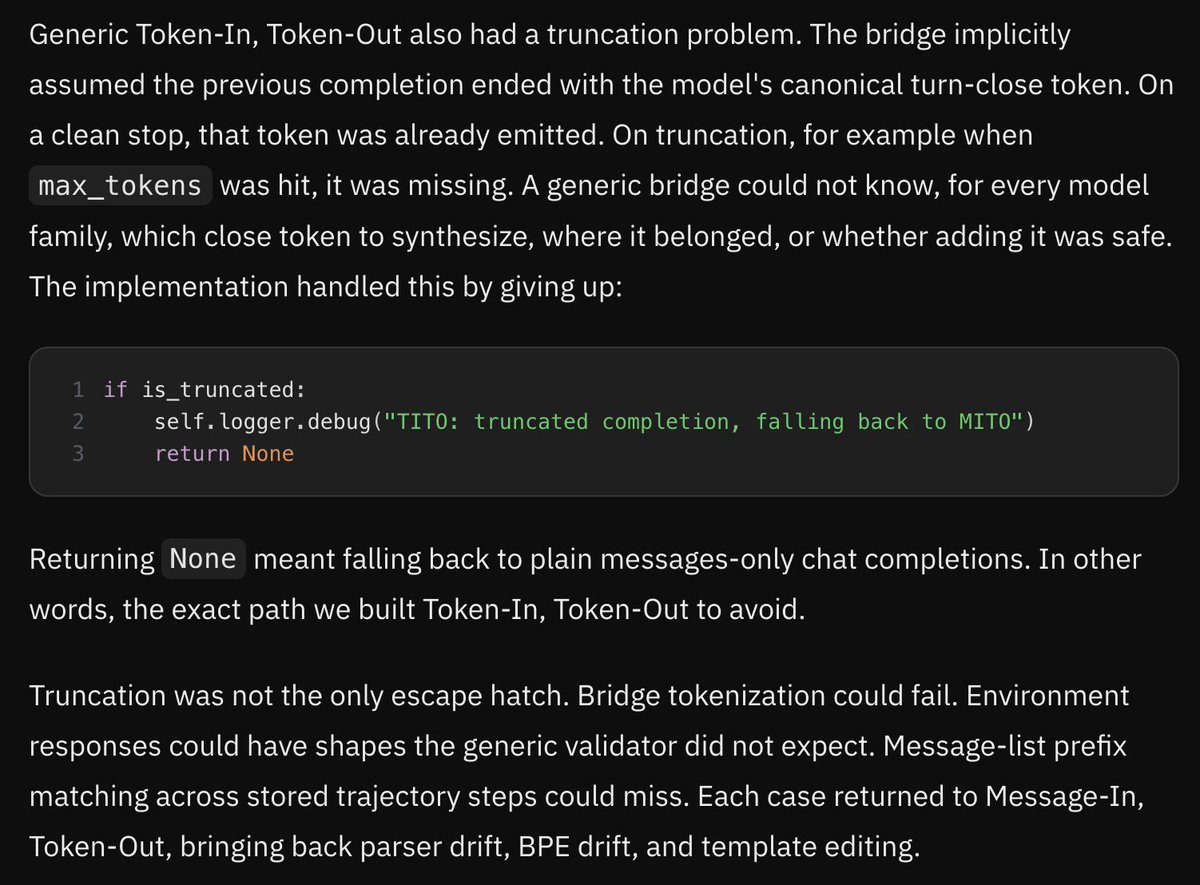
some of our fav bugs on the road to `renderers`
read all about it: https://www.primeintellect.ai/blog/renderers



go render some tokens:
some of our fav bugs on the road to `renderers` read all about it: https://www.primeintellect.ai/blog/renderers
all chat templates are wrong, some chat templates are useful
we found some CRAZY performance wins by patching official templates, and we're shipping them in a standalone library you can use with any RL stack
w/ examples for @vllm_project @sgl_project @huggingface @tinkerapi
Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.
the core of the issue is that both encoding and parsing are many-to-one
vanilla TITO does prefix lookup in token-space, which misses many rendering collisions
the solution is to do lookup in message-space, then input prep in token-space, which we call bridge_to_next_turn

all chat templates are wrong, some chat templates are useful we found some CRAZY performance wins by patching official templates, and we're shipping them in a standalone library you can use with any RL stack w/ examples for @vllm_project @sgl_project @huggingface @tinkerapi
@vllm_project @sgl_project @huggingface @tinkerapi we're intending for this to become a programmable source of truth for template implementations so that we can finally get rid of jinja
lots here already, but PRs welcome for all models!

the core of the issue is that both encoding and parsing are many-to-one vanilla TITO does prefix lookup in token-space, which misses many rendering collisions the solution is to do lookup in message-space, then input prep in token-space, which we call bridge_to_next_turn
@vllm_project @sgl_project @huggingface @tinkerapi from a live run:
We are open sourcing renderers
For RL, the inference server should be simple Tokens in, tokens out
renderers is the token-level chat templating layer to >render messages to tokens >parse completions to structure >bridge rollouts byte-for-byte > >3x throughput on openmodels
Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.
working at prime is just "ugh i had this gnarly problem, let’s fix it and then make it available to everyone"
a ton of other things are coming, can’t wait to show it to yall :)
Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.
never again

Introducing Renderers RL trainers work in tokens. Environments work in messages. Going back and forth corrupts sampled tokens, wasting compute on every agentic turn. With Renderers, we fix this mismatch. This unlocks >3x throughput on popular open models.