Researchers present KL-regularized policy gradient paper at ICLR 2026
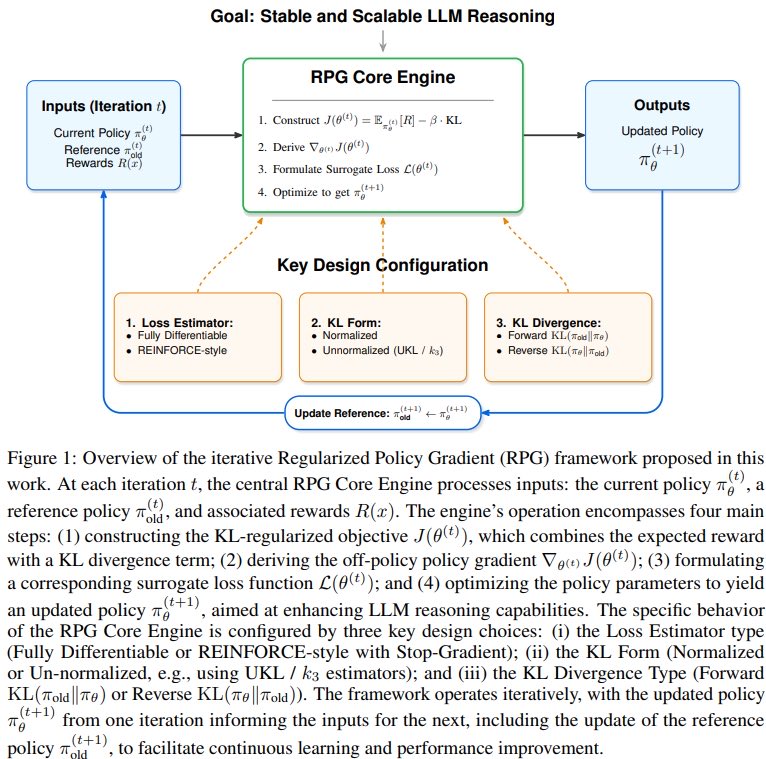
Researchers presented the paper "On the Design of KL-Regularized Policy Gradient Algorithms for LLM Reasoning" at ICLR 2026 in Pavilion 4, booth #4517. The work introduces the Regularized Policy Gradient (RPG) framework and examines KL-regularized policy gradient methods to improve large language model reasoning. The research influenced LLM models V4 and V3.2. Quanquan Gu, Associate Professor of Computer Science at UCLA leading the AGI Lab and Pre-training & Scaling Co-Lead at ByteDance Seed, co-authored the paper.
First post
Why it matters
Yifeng Liu (UCLA AGI Lab PhD student) applied lessons from his prior Kimi-1.5 reinforcement learning project to the Regularized Policy Gradient framework.
Yifan Zhang (Princeton AI Lab Fellow) unified normalized and unnormalized KL regularization variants within the new policy gradient algorithms.
Quanquan Gu (UCLA AGI Lab leader) coauthored work introducing RPG-Style Clip for stable off-policy policy gradient training at scale.
3 more posts
YI
